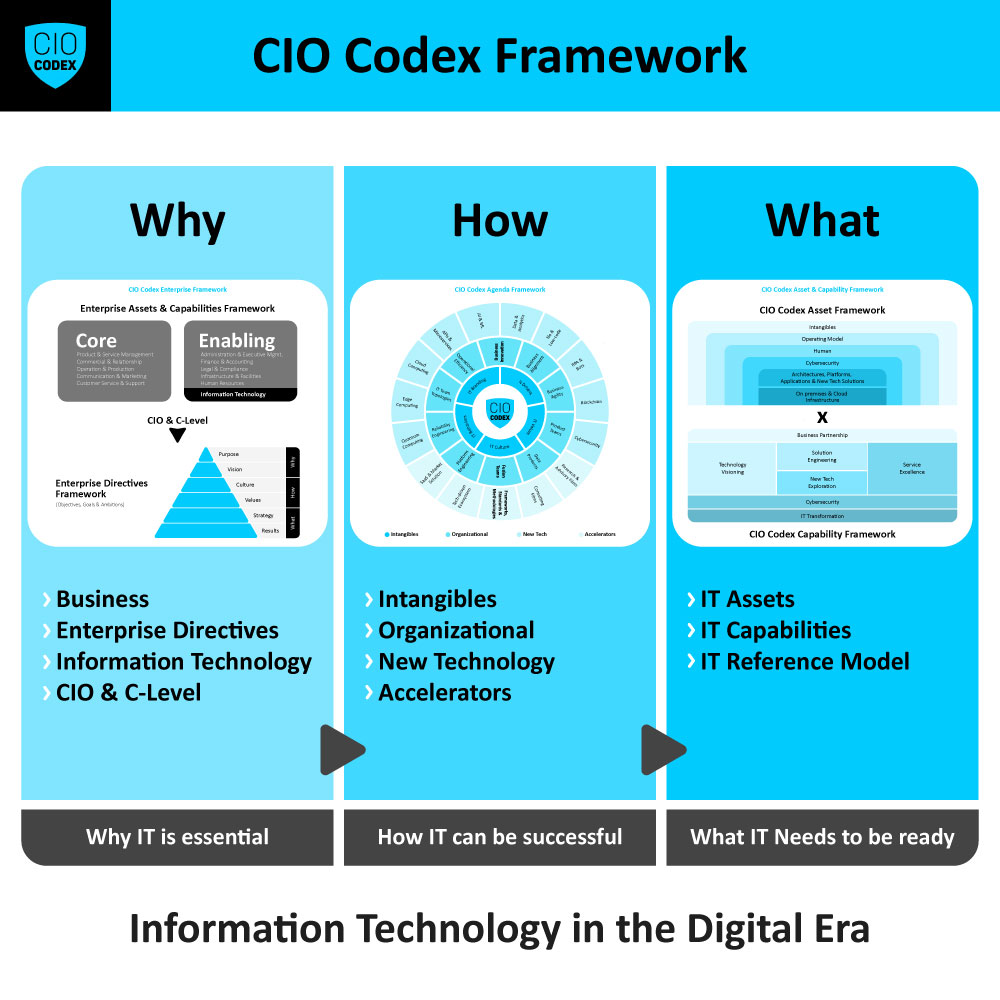
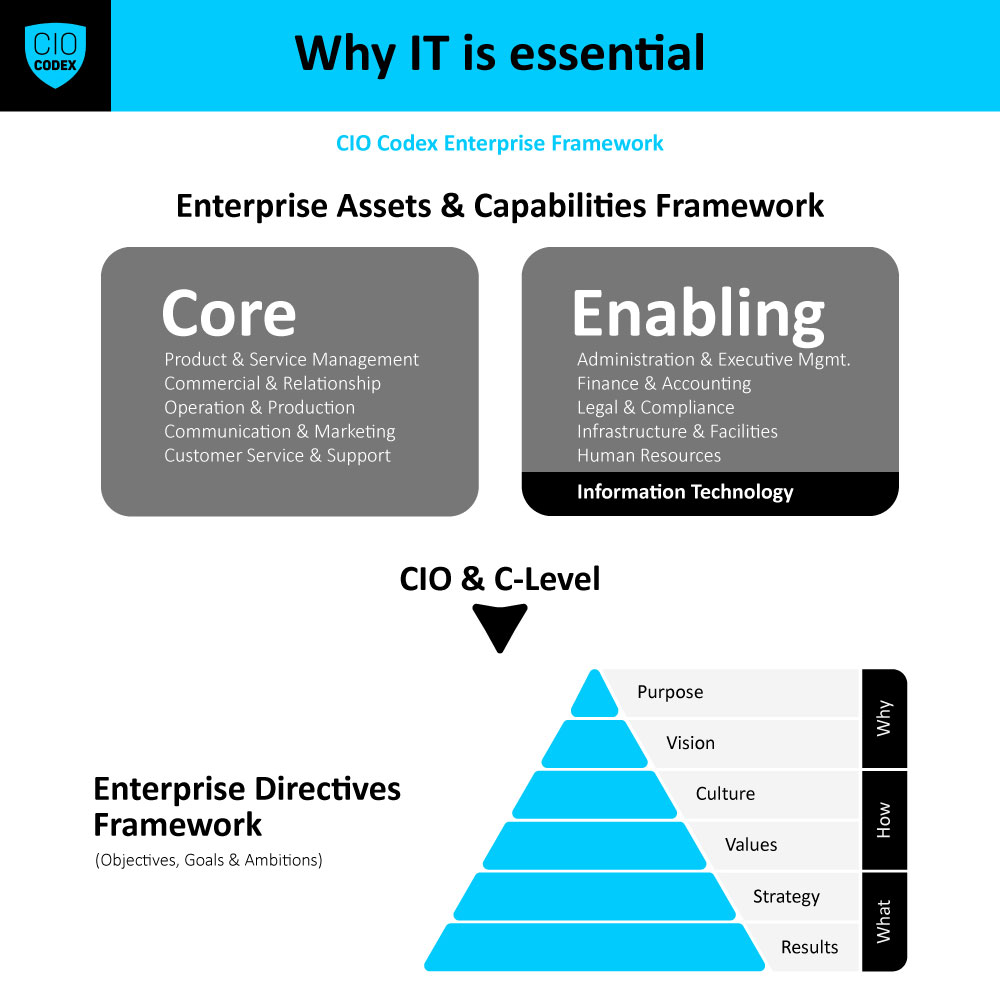

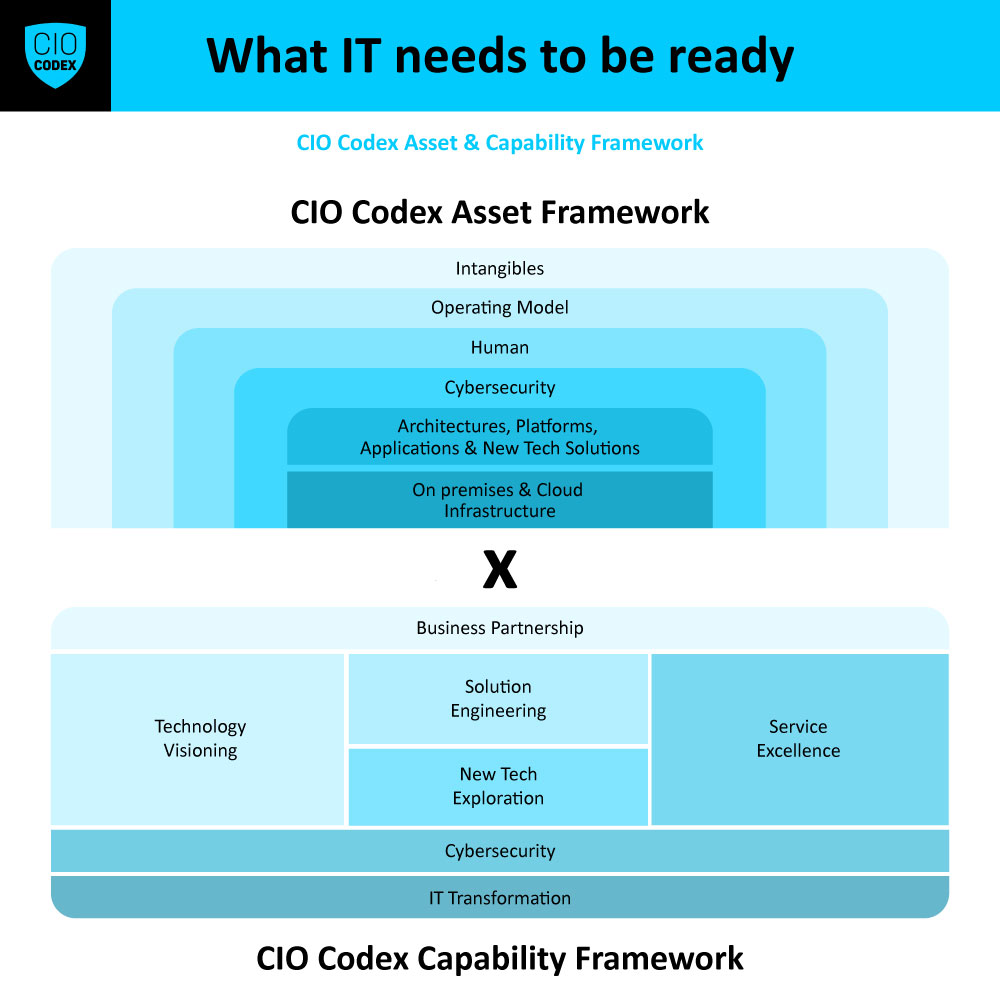


Para o tema Reliability Engineering da camada Organizational, os OKRs devem focar na criação de sistemas confiáveis e resilientes, garantindo a qualidade e a continuidade dos serviços de TI.
Aqui estão alguns exemplos de OKRs que podem ser implementados:
Objetivo 1: Aumentar a confiabilidade dos sistemas de TI.
· KR1: Alcançar um tempo de atividade de 99,99% para os sistemas críticos até o final do ano.
· KR2: Reduzir o tempo médio de recuperação (MTTR) em incidentes críticos em 30% em seis meses.
· KR3: Implementar monitoramento proativo em 100% dos sistemas, detectando potenciais falhas antes de afetarem os usuários.
Objetivo 2: Fortalecer a capacidade de resposta a incidentes de TI.
· KR1: Realizar simulações de incidentes trimestralmente, melhorando a prontidão da equipe em 25%.
· KR2: Desenvolver e implementar um novo plano de resposta a incidentes que reduza a resposta inicial média para menos de 5 minutos.
· KR3: Aumentar a eficiência dos processos de resposta a incidentes, reduzindo o número de incidentes recorrentes em 50%.
Objetivo 3: Melhorar a resiliência dos sistemas de TI.
· KR1: Concluir 3 revisões de arquitetura de sistemas para identificar e remediar pontos únicos de falha.
· KR2: Aumentar a cobertura de testes de resiliência em ambientes de produção em 40%.
· KR3: Estabelecer um programa de treinamento contínuo em engenharia de resiliência para a equipe de TI.
Objetivo 4: Otimizar a engenharia de performance dos sistemas.
· KR1: Melhorar o desempenho do sistema, reduzindo a latência em 20% para as principais aplicações.
· KR2: Implementar melhorias de desempenho que resultem em uma redução de 10% na carga dos servidores.
· KR3: Criar dashboards de performance em tempo real para monitoramento contínuo e ação imediata.
Objetivo 5: Integrar práticas de Site Reliability Engineering (SRE) na gestão de serviços de TI.
· KR1: Treinar 100% da equipe de operações de TI em princípios SRE dentro dos próximos 3 meses.
· KR2: Adotar indicadores de nível de serviço (SLIs) e objetivos de nível de serviço (SLOs) para 75% dos serviços críticos.
· KR3: Estabelecer um processo de post-mortem e aprendizado contínuo para todos os incidentes críticos, aplicando lições aprendidas a futuros projetos de engenharia.
Estes OKRs são essenciais para garantir que a equipe de Reliability Engineering esteja focada não apenas em manter os sistemas funcionando de maneira eficiente, mas também em antecipar problemas e responder de forma eficaz, garantindo que a infraestrutura de TI suporte as operações críticas da empresa e contribua para uma experiência positiva do cliente.




