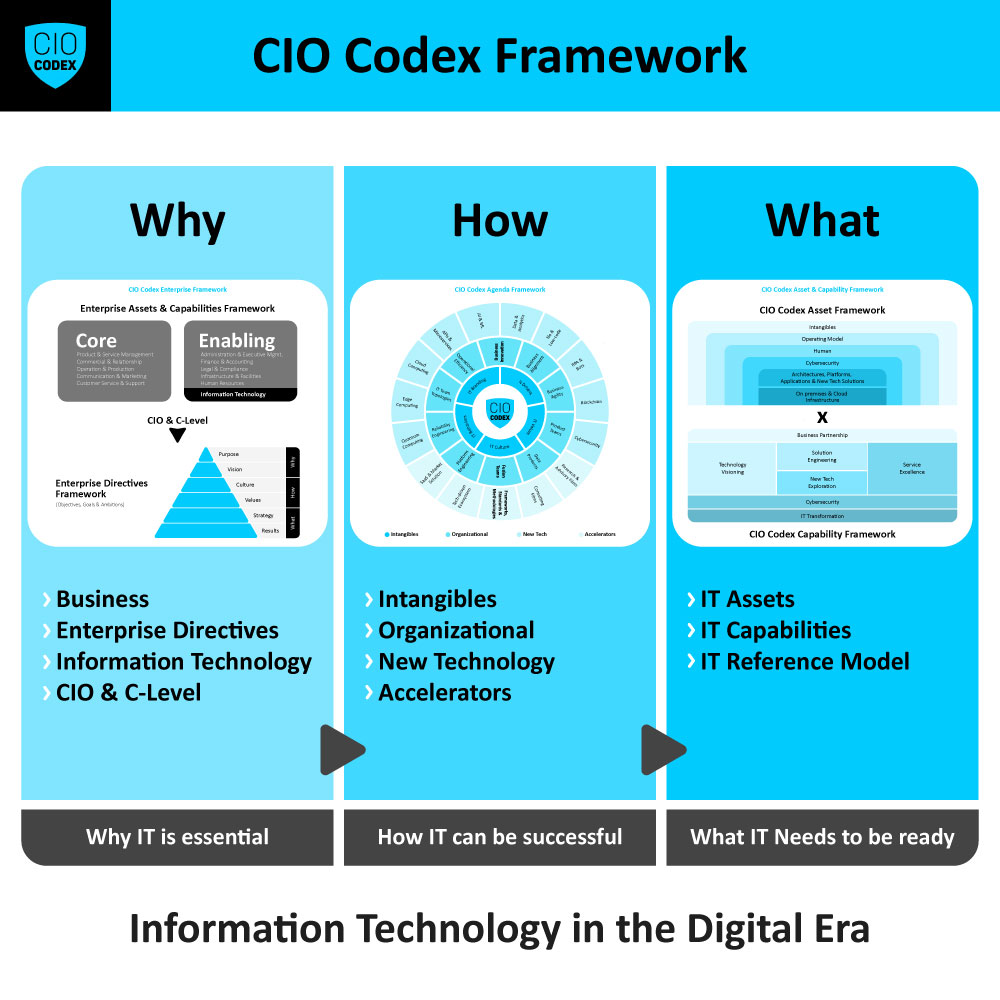
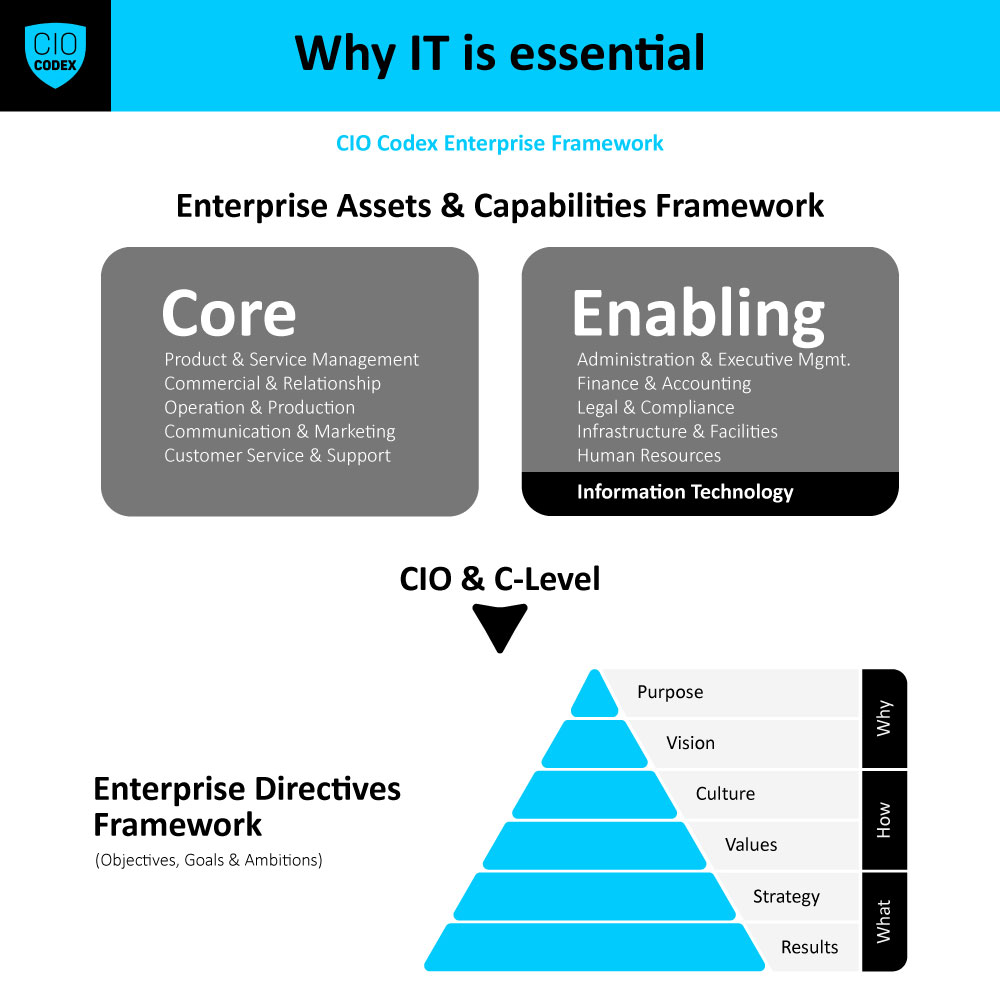

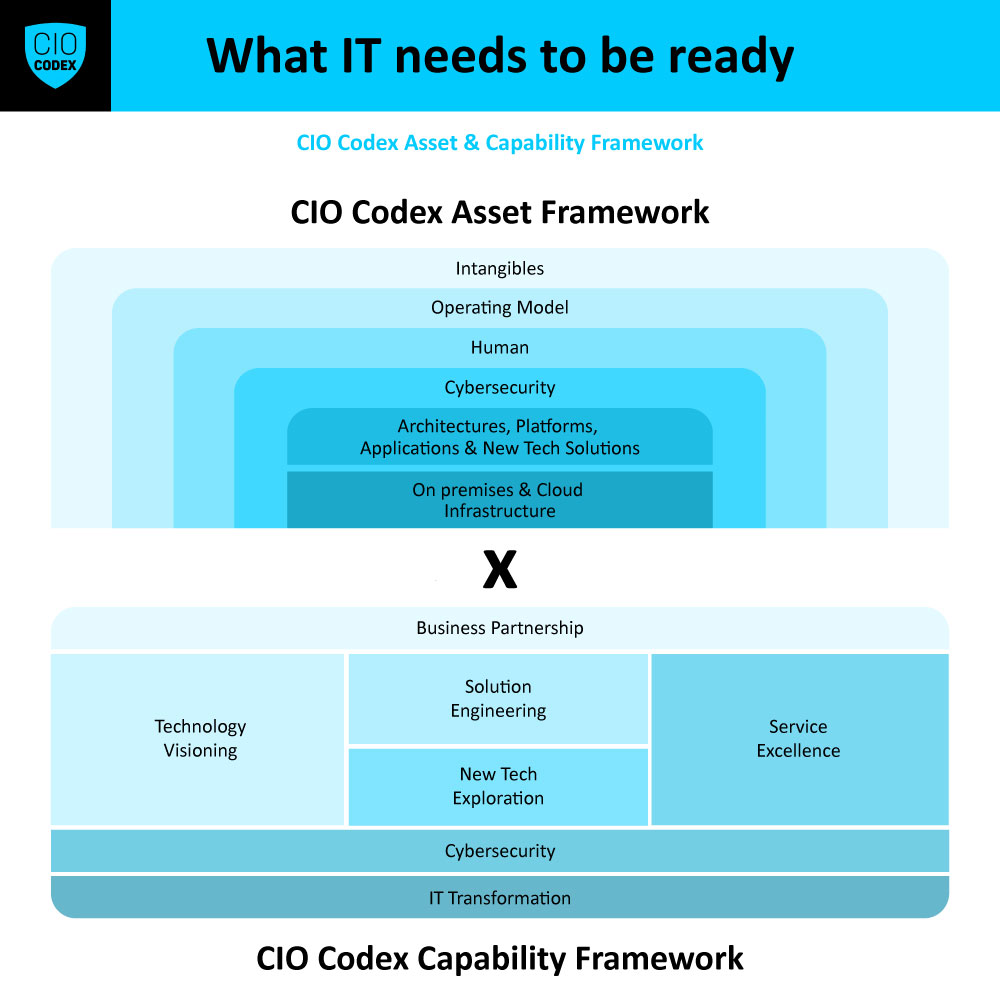


No atual cenário competitivo e em constante evolução, a engenharia de confiabilidade (Reliability Engineering) tornou-se um elemento crítico para a entrega de serviços e sistemas de tecnologia robustos e confiáveis.
Empresas de vanguarda adotam práticas recomendadas pelo mercado que são fundamentais para manter a confiabilidade em todos os níveis operacionais.
Reliability Engineering é uma disciplina que se concentra na prevenção de falhas e na manutenção da qualidade e disponibilidade dos sistemas de TI.
Ela se baseia em uma abordagem proativa para identificar e mitigar riscos antes que eles se transformem em problemas reais, garantindo assim que os sistemas sejam confiáveis e estejam operacionais quando mais necessários.
Práticas Recomendadas:
· Análise Proativa de Riscos e Falhas: Implementação de uma abordagem proativa para a identificação e análise de riscos e falhas potenciais, utilizando técnicas como FMEA (Análise de Modo e Efeito de Falha) e simulações de falhas.
· Design para Confiabilidade: Desenvolvimento de sistemas com redundâncias e mecanismos de tolerância a falhas integrados para garantir a continuidade das operações mesmo em casos de problemas inesperados.
· Monitoramento e Observabilidade: Uso de ferramentas avançadas de monitoramento e observabilidade para detecção precoce de incidentes e desempenho em tempo real.
· Implementação de SRE (Site Reliability Engineering): Adoção de práticas e princípios de SRE para equilibrar a necessidade de lançamento rápido de novas funcionalidades com a estabilidade dos sistemas.
· Cultura de Blameless Postmortems: Promoção de uma cultura que encoraja a análise construtiva de incidentes sem atribuir culpa, focando na aprendizagem e melhoria contínua.
· Automação de Processos Operacionais: Utilização de scripts e ferramentas de automação para realizar tarefas operacionais, reduzindo a carga de trabalho manual e o potencial para erro humano.
· Testes de Carga e Estresse: Execução regular de testes de carga e estresse para validar a capacidade e resiliência dos sistemas sob condições extremas.
· Práticas de DevSecOps: Integração das considerações de segurança desde o início do ciclo de vida do desenvolvimento de software, garantindo que as práticas de segurança sejam parte integrante do processo de engenharia.
· Capacidade de Recuperação e Planejamento de Desastres: Desenvolvimento de estratégias de recuperação de desastres e planos de contingência para assegurar a rápida restauração dos serviços em caso de falhas graves.
· Treinamento e Desenvolvimento de Equipe: Investimento no treinamento e desenvolvimento de competências técnicas da equipe para garantir que todos estejam preparados para gerenciar e responder a incidentes de forma eficaz.
· Gestão Baseada em SLIs, SLOs e SLAs: Definição e gestão de indicadores de nível de serviço (SLIs), objetivos de nível de serviço (SLOs) e acordos de nível de serviço (SLAs) para medir e melhorar continuamente a confiabilidade dos sistemas.
· Feedback Contínuo e Iteração Rápida: Estabelecimento de loops de feedback contínuos entre equipes de desenvolvimento e operações para iterar e melhorar os sistemas de forma rápida e eficiente.
· FinOps para Otimização de Custos: Monitoramento e otimização contínua dos custos de infraestrutura e operações para assegurar a eficiência financeira.
Através da integração dessas práticas de Reliability Engineering, organizações podem alcançar níveis superiores de estabilidade e confiabilidade.
Isso não apenas minimiza o tempo de inatividade e maximiza a satisfação do cliente, mas também serve como um diferencial competitivo no mercado.
Uma implementação eficaz dessas práticas resultará em um ambiente de TI resiliente, preparado para enfrentar os desafios atuais e futuros, mantendo a integridade e a confiança nos sistemas e serviços oferecidos.



