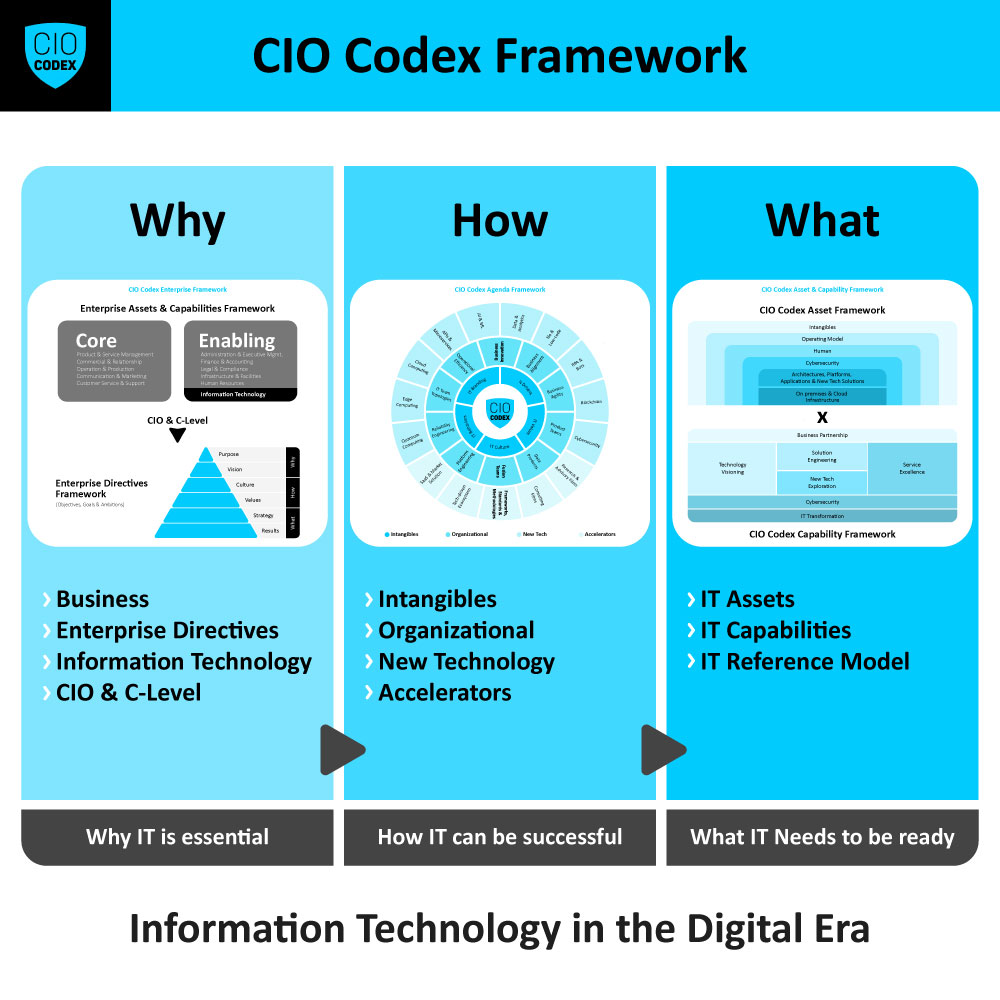
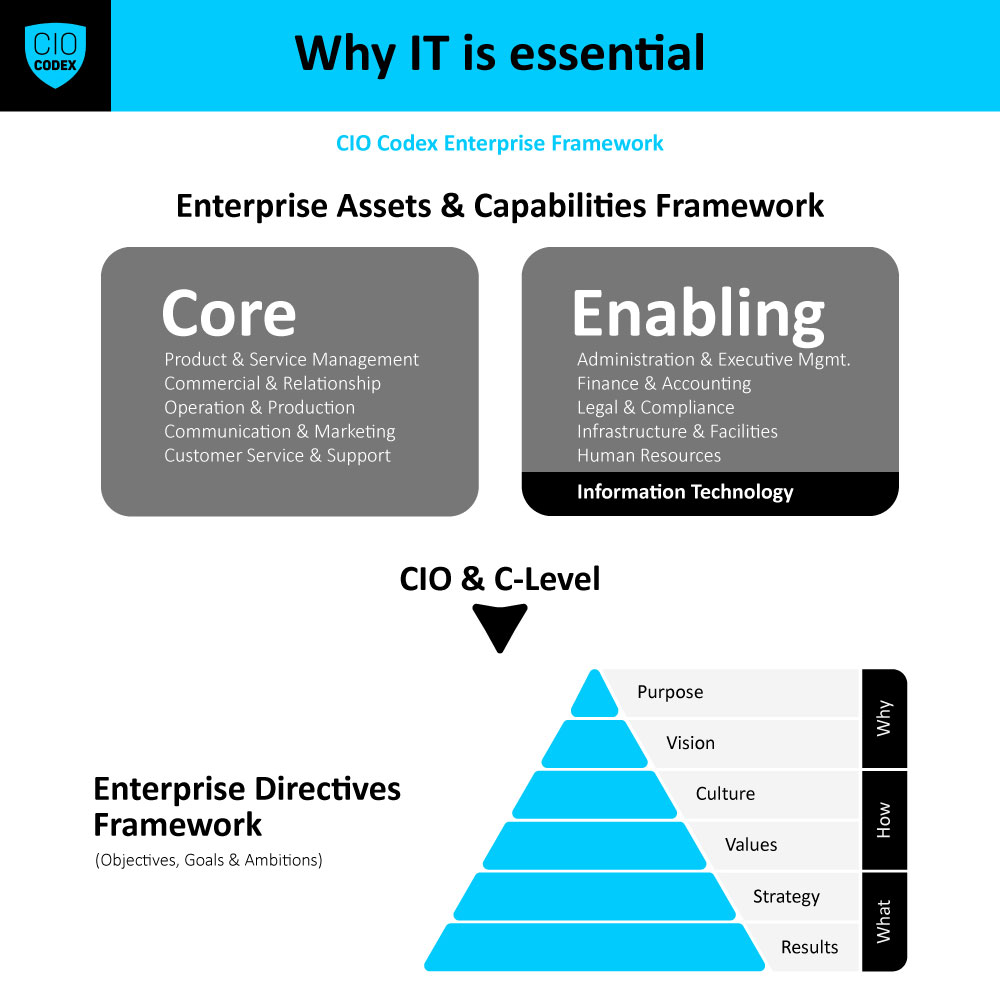

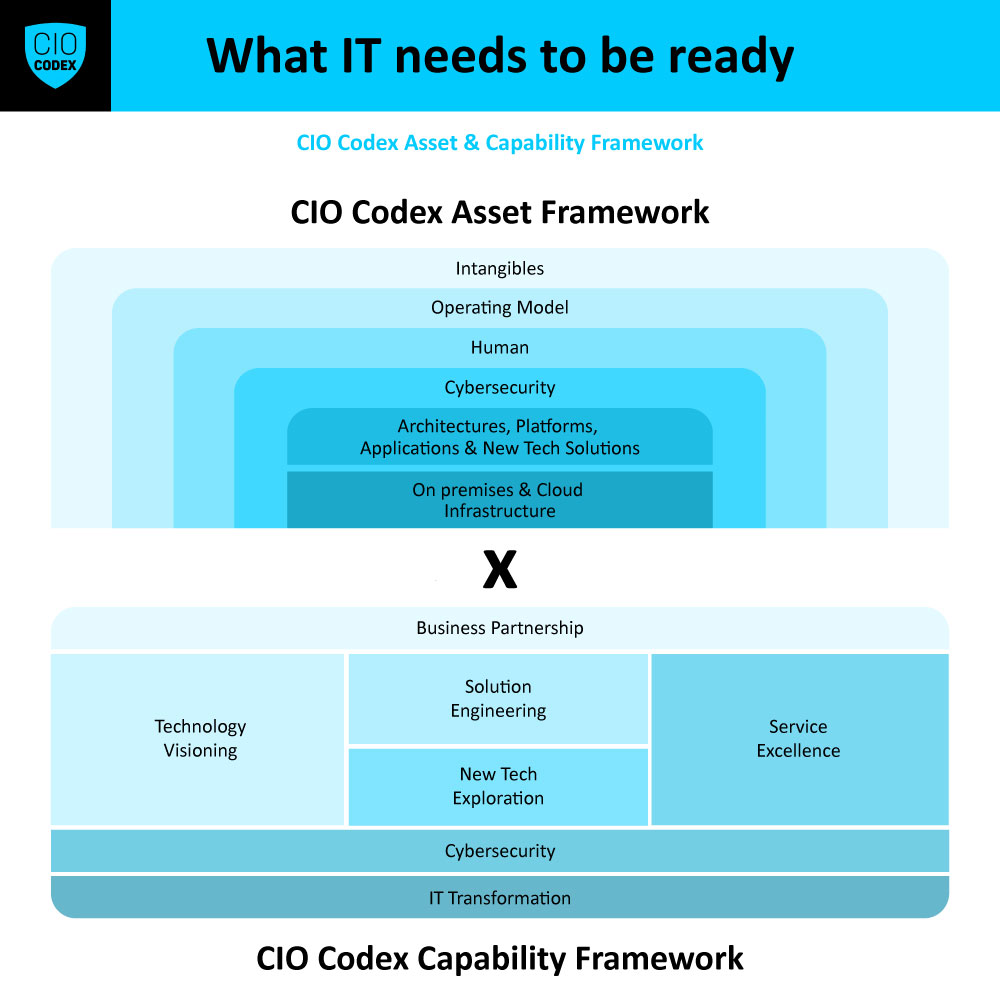


Para o tópico de Reliability Engineering dentro da camada Organizacional, um roadmap de implementação bem-estruturado é vital para assegurar a integridade e a confiabilidade dos sistemas e serviços de tecnologia.
Este roadmap deve refletir uma abordagem sistêmica que incorpore práticas do Site Reliability Engineering (SRE) e DevSecOps para estabelecer um ecossistema tecnológico resiliente e seguro. Abaixo, delineamos as etapas essenciais para este processo.
Reliability Engineering é uma disciplina fundamental que permeia todos os aspectos do ambiente de tecnologia. Sua importância transcende o simples funcionamento dos sistemas, abraçando a total confiabilidade e resiliência operacional.
Incorporando práticas de SRE e DevSecOps, o objetivo é criar um framework onde a confiabilidade é o ponto central da arquitetura operacional, com sistemas e serviços projetados para maximizar o uptime e minimizar as falhas.
Principais Etapas da Implementação:
Definição de Metas e Indicadores de Confiabilidade
· Identificar SLIs (Service Level Indicators), SLOs (Service Level Objectives) e SLAs (Service Level Agreements) que irão orientar as métricas de confiabilidade.
Integração de Práticas SRE
· Estabelecer práticas de engenharia de confiabilidade, como gerenciamento de incidentes e post-mortems, para aprender com as falhas e melhorar continuamente.
Adoção de DevSecOps
· Integrar segurança e operações no ciclo de vida do desenvolvimento, promovendo uma cultura de colaboração entre desenvolvimento, operações e segurança.
Capacitação e Treinamento
· Prover treinamento contínuo para equipes de desenvolvimento e operações em práticas de SRE e DevSecOps.
Implementação de Automação e Orquestração
· Automatizar processos de deployment e operações para reduzir o potencial de erro humano e aumentar a eficiência.
Desenvolvimento de Sistemas Resilientes
· Projetar e construir sistemas com tolerância a falhas e capacidade de recuperação rápida após incidentes.
Monitoramento Contínuo
· Implementar soluções de monitoramento em tempo real para identificar e resolver proativamente os problemas.
Gestão de Mudanças
· Gerenciar mudanças de forma a não comprometer a estabilidade dos sistemas em produção.
Feedback e Melhoria Contínua
· Estabelecer ciclos de feedback que permitam a iteração rápida e a melhoria contínua dos sistemas.
Revisão de Processos
· Revisar periodicamente os processos de operações para alinhamento com as melhores práticas e tecnologias emergentes.
Medição e Análise de Desempenho
· Mensurar regularmente o desempenho contra os SLOs estabelecidos, analisando tendências e identificando áreas para melhoria.
Governança e Compliance
· Assegurar que todas as práticas estejam em conformidade com as regulamentações vigentes e padrões da indústria.
Esta estrutura não apenas fornece um caminho claro para o desenvolvimento e operação de sistemas, mas também estabelece uma base sólida para uma cultura organizacional onde a confiabilidade é a prioridade máxima.
Ao seguir este roadmap, as organizações podem se posicionar para gerenciar efetivamente os riscos operacionais e atender ou superar as expectativas dos stakeholders.



