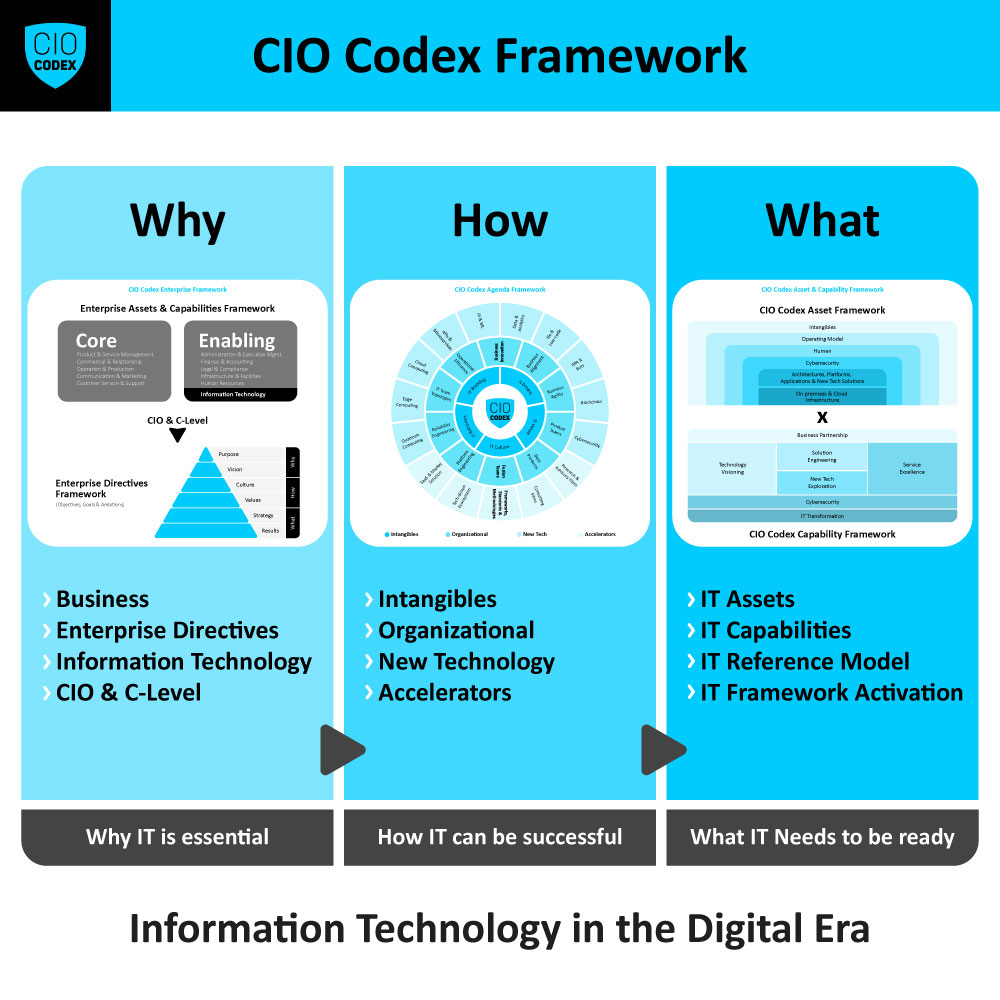
CIO Codex E-book
Uma introdução clara ao CIO Codex Framework, com os pilares essenciais para transformar TI em valor. Ideal para ter a visão geral do framework.
Como já comentei em alguns artigos, em um mundo cada dia mais digital, nada mais natural do que se dar a atenção proporcional para Cybersecurity.
No cenário corporativo atual, marcado por ameaças cibernéticas crescentes e sofisticadas, a segurança da informação emergiu como um pilar central na estratégia de qualquer organização.
Líderes de TI estão na vanguarda, não apenas implementando soluções tecnológicas, mas também promovendo discussões estratégicas essenciais para alinhar as políticas de segurança com os objetivos de negócio da empresa
Quando pensamos em Cybersecurity imediatamente pensamos em hackers e uma visão primordialmente tecnológica da coisa.
Mas quando se pensa na TI como um todo, existe um conjunto muito mais amplo de aspectos a serem considerados e endereçados.
Inclusive, amplo o suficiente para serem considerados e colocados na pauta de várias áreas dentro e fora da TI, em uma abrangência que vai muito além da "área de segurança".
Aqui um artigo muito interessante da CIO Online, justamente destacando essa abrangência de macro temas a serem considerados, envolvendo arquitetura, riscos, desenvolvimento e diversas outras áreas além do "CISO":
https://www.cio.com/article/650903/7-tough-it-security-discussions-every-it-leader-must-have.html
O artigo destaca a importância de discussões contínuas sobre estratégias de segurança da informação, sublinhando que tais conversas são indispensáveis para a integração de iniciativas de cibersegurança aos objetivos de negócio da empresa.
Segundo o mesmo, estas discussões ajudam a empresa a se alinhar em torno de estratégias eficazes e robustas, lidando com requisitos regulatórios em mudança e identificando vulnerabilidades e ameaças para mitigação de riscos.
Adicionalmente, líderes de TI são encorajados a questionar se os sistemas da organização estão modernizados o suficiente para garantir segurança, se os cenários de ciberataques são adequadamente abordados e se há uma cultura de segurança sendo cultivada em todos os níveis da organização.
O papel da alta liderança em tais conversas é crucial, pois define o tom e a urgência com que as questões de segurança são tratadas.
É também enfatizada a necessidade de planos de resposta a incidentes eficazes e atualizados, bem como uma avaliação contínua do retorno sobre o investimento em soluções de segurança.
A discussão estratégica entre líderes de TI e partes interessadas é vital para alinhar as iniciativas de cibersegurança com os objetivos de negócio da organização.
Esta integração é crucial para a adaptação às mudanças regulatórias e para a identificação e mitigação de ameaças emergentes.
A clareza nesses diálogos garante que todos os recursos de segurança estejam sincronizados com as metas estratégicas e operacionais.
Questionar a modernidade dos sistemas de TI é fundamental para garantir sua segurança.
A transição para arquiteturas modernas, como as nuvens públicas e privadas, deve ser priorizada, pois integram a segurança diretamente na infraestrutura, fortalecendo a defesa contra ataques cibernéticos e alinhando a infraestrutura de TI com as práticas modernas de desenvolvimento de software.
Simulações e discussões de cenários de ciberataques são essenciais para avaliar e fortalecer a capacidade de resposta a incidentes.
Envolver gestores e funcionários em planejamentos regulares de resposta a incidentes enriquece a preparação da organização e estabelece procedimentos claros e eficazes para a gestão de crises.
Promover uma cultura de segurança em todos os níveis da organização é fundamental.
Líderes devem incentivar práticas de segurança proativas, educando e capacitando funcionários a operar dentro de diretrizes claras de segurança. Uma cultura robusta de segurança acelera a inovação e protege os resultados do negócio.
Manter-se atualizado sobre as ameaças emergentes permite que os líderes de segurança adaptem estratégias para enfrentar novos desafios.
Discussões diretas sobre tendências recentes em ameaças cibernéticas são cruciais para reorientar as estratégias de defesa e realocar recursos de TI para infraestruturas mais seguras, como serviços em nuvem.
É crucial discutir como os investimentos em segurança estão protegendo ativos e reduzindo riscos.
Avaliar continuamente o retorno sobre o investimento ajuda a justificar os gastos e adaptar as estratégias à medida que o ambiente de ameaças evolui.
Melhorar a visibilidade e a gestão dos controles de segurança, processos e regulamentações maximiza o retorno sobre os investimentos em segurança.
Uma outra matéria recente abordou o aspecto da GPDR da Europa de forma associada ao tema de Cybersecurity, sob a perspectiva de privacidade de dados.
Tenho dúvidas se as regulações americanas (pelo visto lá existe muita coisa específica por cada estado) abordam "apenas" esse tema de dados ou se exploram outros aspectos.
Creio que já estamos no caminho por aqui a partir da LGPD, mas se forem aspectos diferentes, possivelmente em algum futuro próximo teremos outras regulações de segurança a serem importadas para cá.
Alguns artigos estão falando que as perdas por temas de Cybersecurity serão algo na casa de USD 10,5 trilhões ao ano por volta de 2025 (que está logo ai).
Em um primeiro impulso eu até pensei que poderia ser uma hype na linha do Metaverso, mas na mesma matéria colocam que essa cifra seria um aumento na ordem de 300% versus os números de 2015, o que me parece ser, ao menos em grandes números, algo plausível, pois (infelizmente) nessa corrida de gatos e ratos, os ratos têm sido cada vez mais espertos.
E eu não cheguei a ler nada a respeito ainda, mas acho que seria natural esperar que os avanços tecnológicos atuais deverão trazer novas e melhores ferramentas para ambos os lados.
O que será que pode representar o poder da AI, Cloud, conectividade 6G ou até mesmo Quantum Computing sendo usados para o crime?
Acho que é legítimo pensar que podem no mínimo representar todo um novo mundo de oportunidades a serem exploradas, por ambos os lados, seja para atacar, seja para defender.
Acho que vale analisar sob a perspectiva do mercado de trabalho. Muito se falar sobre inúmeras oportunidades em Data Analytics e agora mais fortemente em AI, e com toda a razão, afinal são temas com ainda muito espaço para crescer.
Mas uma área que acaba muitas vezes não recebendo o mesmo destaque (será que é por ser menos "fancy"?) é justamente Cybersecurity. E considerando o exposto no artigo, tem tudo para ser (e provavelmente já é) uma área cheia de oportunidades.
Tenho a impressão (embora sem base em números, é só percepção mesmo) que os canais e mecanismos de formação são menores (ou divulgados em menor escala) que os outros temas com mais hype em IT.
Para quem busca um espaço em IT, vale avaliar essa área, muito embora, fica igualmente minha percepção de que aqui a régua é mais alta e é preciso já ter algum nível mínimo de conhecimento técnico para buscar então esse tipo de especialização.
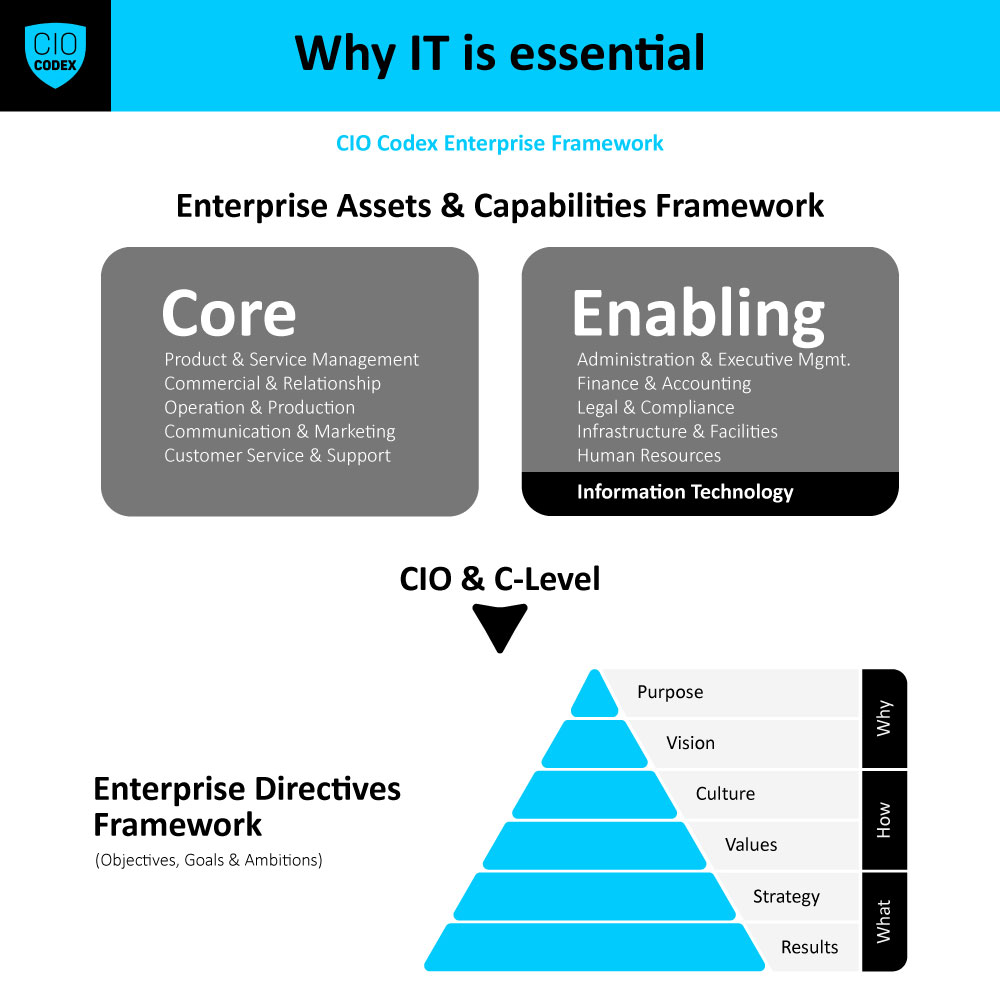
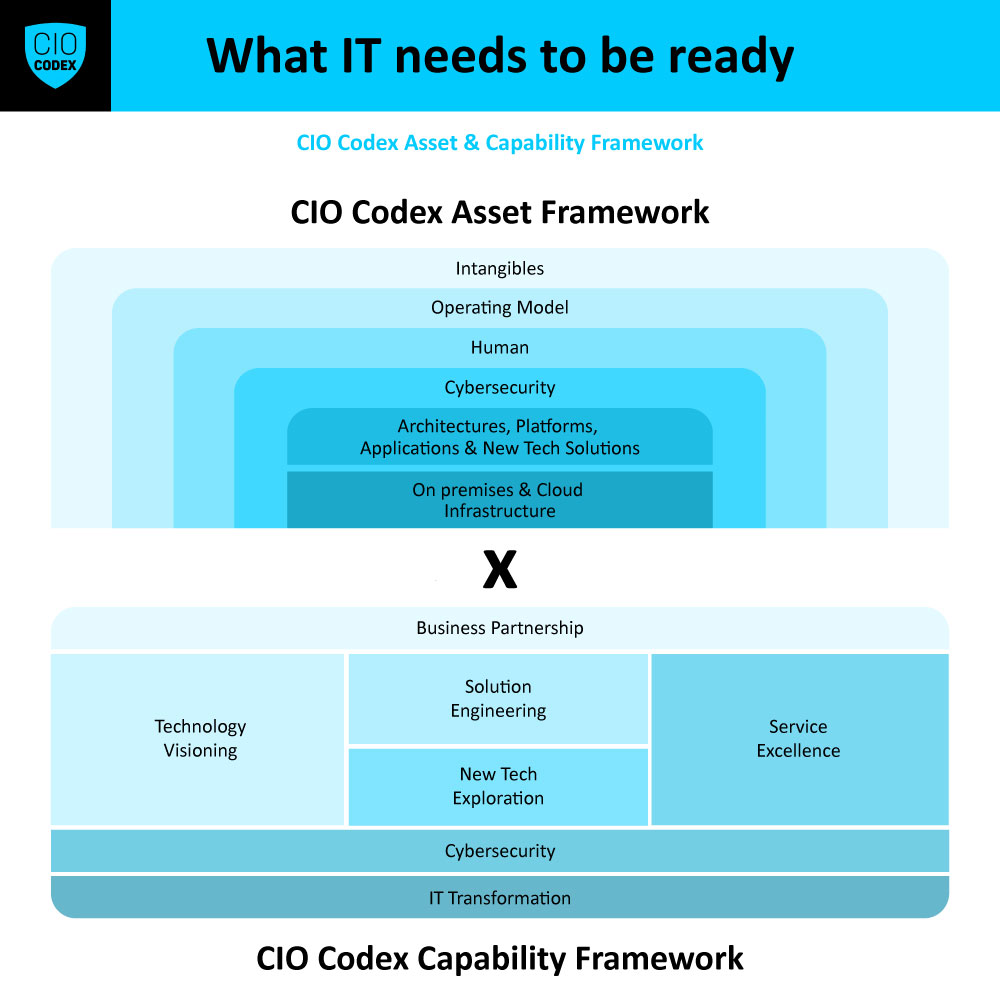
Cybersecurity é um tema de vital importância na camada New Tech do CIO Codex Agenda Framework, refletindo uma necessidade crítica no cenário digital contemporâneo.
Este tema aborda as estratégias, tecnologias e práticas destinadas a proteger sistemas, redes e programas de ataques digitais.
O conteúdo complementar explora a complexidade crescente do cenário de ameaças cibernéticas e como as organizações podem desenvolver uma abordagem robusta para proteger suas informações e infraestruturas críticas contra uma variedade de riscos.
A introdução ao tema Cybersecurity enfatiza a importância de uma abordagem abrangente e multidimensional para a segurança cibernética.
Esta abordagem não se limita apenas à tecnologia, mas engloba processos, políticas, formação de equipes e cultura organizacional.
É discutido como a segurança cibernética é fundamental não apenas para a proteção de dados e sistemas, mas também para a manutenção da confiança dos clientes, a proteção da reputação da marca e a conformidade com regulamentos e padrões.
Este conteúdo explora os diversos aspectos da Cybersecurity, incluindo a identificação de riscos, a proteção de ativos de TI, a detecção de ameaças, a resposta a incidentes e a recuperação de ataques.
São abordadas as tecnologias e práticas mais recentes em segurança cibernética, como criptografia avançada, autenticação multifatorial, inteligência artificial e aprendizado de máquina para a detecção de ameaças, bem como a importância de estratégias proativas como a análise de riscos e a realização de testes de penetração.
Além disso, são examinados os desafios em manter um ambiente de TI seguro, como a rápida evolução das ameaças cibernéticas, a complexidade crescente dos sistemas de TI e a escassez de profissionais qualificados em segurança cibernética.
São discutidas estratégias para construir e manter uma equipe de segurança cibernética eficaz, a necessidade de treinamento contínuo e conscientização em todos os níveis da organização, e a importância de colaborações e compartilhamento de informações sobre ameaças dentro da comunidade de segurança cibernética.
Por fim, o conteúdo destaca como medir a eficácia das iniciativas de Cybersecurity, incluindo a avaliação da postura de segurança, o monitoramento de indicadores-chave de desempenho e a realização de auditorias regulares.
É enfatizada a necessidade de uma abordagem dinâmica e adaptativa à segurança cibernética, que possa responder às mudanças no ambiente de ameaças e às novas exigências regulatórias.
Os componentes de cybersecurity extrapolam em muito os aspectos tecnológicos e devem ser considerados dentro de um Programa de Cybersecurity.
A criação de um programa de cibersegurança robusto e eficaz requer a definição e implementação de várias estruturas e processos chave.
Os componentes principais de um programa de cibersegurança incluem o mandato executivo, modelo de referência, estruturas de governança, plano estratégico anual e processos de segurança.
Cada um desses componentes é essencial para a criação de um programa de cibersegurança que não apenas protege a organização contra ameaças imediatas, mas também contribui para sua estabilidade e crescimento a longo prazo.
1) – Enterprise security charter: Executive mandate
O mandato executivo, ou carta de segurança empresarial, estabelece a autoridade e o compromisso da liderança sênior com a segurança cibernética.
Este documento é crucial porque define o tom e o suporte para todas as iniciativas de segurança dentro da empresa.
Ele deve esclarecer as expectativas da liderança, os recursos alocados e as responsabilidades de segurança em todos os níveis organizacionais.
A presença de um mandato claro e forte do executivo é um indicador de que a segurança é uma prioridade estratégica, não apenas uma necessidade operacional ou uma resposta a regulamentações.
2) – Terms of reference: Reference mode
Os termos de referência descrevem o escopo, os objetivos e os padrões específicos que orientam o programa de cibersegurança.
Eles servem como um modelo de referência que define as práticas, os procedimentos e os benchmarks contra os quais o programa será desenvolvido e avaliado.
Este componente é fundamental para assegurar que o programa de segurança esteja alinhado com as melhores práticas da indústria e com as necessidades específicas da empresa.
O modelo de referência ajuda a garantir consistência e qualidade nas iniciativas de segurança, facilitando também a comunicação e o entendimento claros dos objetivos de segurança em toda a organização.
3) – Governance structures: Accountability
As estruturas de governança referem-se ao conjunto de políticas, procedimentos e responsabilidades estabelecidos para gerir e monitorar o programa de cibersegurança da organização.
A responsabilidade é fundamental neste contexto, pois define quem é responsável por cada aspecto da segurança, desde a tomada de decisões até a implementação e a supervisão das políticas de segurança.
Uma governança eficaz assegura que haja clareza de responsabilidades, transparência nas decisões e um mecanismo para a prestação de contas.
Isso não só aumenta a eficácia do programa de segurança, mas também reforça a confiança de todas as partes interessadas na capacidade da organização de proteger seus ativos.
4) – Annual strategy plan: Roadmap
O plano estratégico anual, ou roteiro, é o plano detalhado que define como as metas de segurança serão alcançadas durante o ano.
Este plano deve incluir objetivos específicos, iniciativas prioritárias, recursos necessários e prazos para implementação.
O roteiro serve como um guia para a equipe de segurança, garantindo que todos os esforços estejam alinhados com as metas estratégicas da empresa e com as expectativas dos stakeholders.
Ele também facilita a avaliação periódica do progresso e os eventuais ajustes das estratégias conforme necessário para responder a novos desafios e oportunidades.
5) – Security processes: Execution
Finalmente, os processos de segurança referem-se à execução prática das estratégias e políticas de segurança.
Este componente abrange a implementação de controles técnicos, a condução de auditorias e testes de penetração, a gestão de incidentes e a formação contínua dos funcionários.
A eficácia dos processos de segurança é crucial para a capacidade da organização de detectar, prevenir e responder a ameaças cibernéticas.
A execução rigorosa e eficiente dos processos de segurança garante que as medidas de proteção estejam sempre atualizadas e sejam eficazes, minimizando assim os riscos para a empresa e maximizando a confiança dos clientes e parceiros.
A trajetória da segurança cibernética é marcada por desenvolvimentos significativos que refletem as mudanças nas demandas tecnológicas e empresariais.
A seguir é apresentada uma visão detalhada da evolução cronológica da segurança cibernética, desde suas origens conceituais até as inovações mais recentes, ilustrando como essa disciplina revolucionou a infraestrutura de TI nas organizações.
A segurança cibernética continua a evoluir, respondendo tanto às oportunidades tecnológicas quanto aos desafios operacionais.
À medida que novas tecnologias emergem e as ameaças evoluem, as estratégias de segurança devem permanecer ágeis e adaptativas.
A capacidade de uma organização de se adaptar eficientemente será crucial para manter a competitividade e a segurança em um ambiente empresarial que é, por natureza, volátil e em constante evolução.
1) – As Origens da Segurança Cibernética (Anos 1970 – 1990)
2) – A Era da Internet e a Expansão da Ameaça (Anos 1990 – 2000)
3) – A Era dos Ataques Sofisticados (2000 – 2010)
5) – O Futuro da Segurança Cibernética
Em suma, a evolução da segurança cibernética tem sido uma jornada de transformação contínua, marcada por avanços tecnológicos significativos e desafios complexos.
À medida que essas tecnologias continuam a se desenvolver, elas prometem transformar ainda mais a forma como as organizações operam, oferecendo novos insights e oportunidades para inovação e proteção.
A cibersegurança, um campo crítico da tecnologia, evoluiu para se tornar uma complexa malha de práticas, soluções e regulamentos destinados a proteger sistemas, redes e programas de ataques digitais.
Em sua essência, a cibersegurança é a aplicação de tecnologias, processos e controles projetados para proteger sistemas, redes e dados de ciberataques.
Efetiva cibersegurança reduz o risco de ataques cibernéticos e protege contra a exploração não autorizada de sistemas, redes e tecnologias.
Alguns conceitos e características se destacam nesse tema, como os apontados a seguir:
Confidencialidade, Integridade e Disponibilidade (CID)
A CID é um modelo que guia as políticas de segurança da informação para proteger a privacidade dos dados, prevenir erros e inacessibilidade.
Criptografia
Um método essencial de proteger informações, transformando-as em um código para prevenir acessos não autorizados.
Segurança de Rede
Inclui medidas para proteger a infraestrutura de TI contra intrusões, como firewalls, anti-malware, e sistemas de detecção de intrusão.
Segurança de Aplicações
Foca no manter o software e os dispositivos livres de ameaças. Um aplicativo comprometido poderia prover acesso a dados projetados para serem protegidos.
Recuperação de Desastres/Business Continuity Planning
Prepara a organização para responder a incidentes de cibersegurança e retomar as operações normais o mais rápido possível.
Características da Cibersegurança:
Adaptação Contínua
O campo exige uma adaptação e atualização contínua em resposta a novas ameaças e tecnologias emergentes.
Abordagem em Camadas
Segurança eficaz exige uma defesa em camadas, que inclui medidas físicas, técnicas e administrativas.
Treinamento e Conscientização
Fundamental para a cibersegurança é a educação contínua dos usuários sobre as melhores práticas de segurança.
Uso de Inteligência Artificial (AI)
AI e machine learning estão cada vez mais sendo incorporados para prever e identificar ameaças de forma proativa, analisando padrões de ataques e respondendo a eles mais rapidamente do que os humanos.
Regulamentações e Compliance
A cibersegurança é fortemente regulada por leis e normas que ditam como as informações devem ser protegidas. GDPR, HIPAA e outras regulamentações impõem padrões e penalidades para garantir a proteção de dados.
A cibersegurança moderna não só é definida pelo desenvolvimento e implementação de soluções defensivas, ela também incorpora uma abordagem proativa que inclui a simulação de ataques (pentesting) e a construção de ambientes resilientes capazes de se adaptar e responder a ameaças persistentes e evolutivas.
Ao mesmo tempo, os profissionais da área devem considerar as implicações éticas do uso de AI na cibersegurança, tanto para aprimorar as defesas quanto para antecipar e se proteger contra o uso mal-intencionado da AI por agentes adversários.
A intersecção entre AI e cibersegurança é um território rico em potencial para o desenvolvimento de sistemas mais inteligentes e autônomos, mas também carrega a necessidade de vigilância constante e atualização de conhecimento para enfrentar os desafios que surgem com a evolução tecnológica.
O propósito da Cybersecurity na camada de New Technology é robustecer a proteção aos ataques digitais, garantindo a segurança dos dados sensíveis e a resiliência dos sistemas de TI.
A integração da Inteligência Artificial (AI) em estratégias de segurança cibernética representa um avanço significativo, permitindo respostas mais ágeis e inteligentes a ameaças em evolução constante.
Objetivos da Cybersecurity integrada com AI:
Ao abraçar a AI como um componente crítico na estratégia de cybersecurity, as organizações podem não apenas reforçar suas defesas contra agentes maliciosos, mas também avançar em direção a uma postura proativa, onde antecipar e neutralizar riscos se torna parte integrante do ecossistema tecnológico.
As discussões em torno da segurança da informação não são meramente técnicas, afinal elas são essencialmente estratégicas e necessárias para a sustentabilidade do negócio.
A partir do que foi apresentado, considero que tais diálogos devem ser uma prática regular e engajar não apenas os líderes de TI, mas todos os executivos da empresa.
Estabelecer uma cultura de segurança robusta e responsiva não é apenas sobre implementar as melhores ferramentas, mas sobre integrar profundamente a segurança no ethos e nas operações diárias da empresa.
Afinal, num mundo onde as ameaças evoluem rapidamente, a adaptabilidade e o compromisso contínuo com a segurança são o que verdadeiramente protegerão nossos ativos mais valiosos.
Julgo relevante reforçar a necessidade de manter essas conversas críticas em todos os níveis da organização, garantindo que a segurança seja percebida não como um custo, mas como um investimento essencial na resiliência e no futuro do negócio.
Cada tópico abordado aqui é crucial para desenvolver uma estratégia de segurança da informação robusta que proteja a organização contra ameaças imediatas e fortaleça sua resiliência a longo prazo, enquanto alinha-se com os objetivos de crescimento e sucesso no mercado.
Hoje em dia a disciplina de Observabilidade, e diria que de forma mais ampla, as próprias capabilities de SRE e Platform Engineering, ganhou uma relevância e atenção muito maior que grande parte das empresas.
O fato, ao menos na minha opinião, é que observabilidade é um "must have" para qualquer aplicação ou serviço nos dias de hoje onde a tolerância à falhas, degradação de performance ou mesmo indisponibilidade de serviços é cada dia mais baixa em um mundo cada dia mais digital.
E acho que vale pontuar o lado "filosófico" dessa disciplina, pois TI também é cultura e Sócrates se aplica perfeitamente à Observability: "quanto mais sei, mais sei que nada sei"!
E quando se fala em observabilidade é muito difícil deixar de lembrar ou falar sobre a plataforma Grafana.
Li esses dias uma matéria da InfoWorld comentando sobre isso:
https://www.infoworld.com/article/3699258/how-grafana-made-observability-accessible.html
A evolução da observabilidade, em sua jornada de uma década desde o lançamento do Grafana, evidencia uma mudança significativa nas práticas de desenvolvimento e operação de sistemas.
Achei muito legal conhecer um pouco da história por trás do Grafana ao longo desses últimos anos, um projeto de código aberto que transformou a observabilidade de uma disciplina especializada para uma ferramenta essencial na era do "você constrói, você executa".
Confesso que não tinha ideia de toda a trajetória de mercado desde o lançamento até os dias atuais.
Não imaginava que o Grafana tinha 10 anos, algo que, pensando bem, é relativamente recente (comparado com outros gigantes do setor de tecnologia que por vezes já ultrapassaram a barreira dos 100 anos), mas ainda assim, nessa década já deixou sua marca e conquistou seu espaço no dia a dia de qualquer área de tecnologia.
Acabamos nos acostumando em ter essas soluções disponíveis e acabamos nem nos dando conta dos caminhos que levaram até elas.
Há dez anos, a introdução do Grafana pelo criador Torkel Ödegaard marcava o início de uma nova era para a observabilidade de sistemas.
Originalmente concebido para melhorar a visualização do comportamento e desempenho dos serviços através da integração com o Graphite, o Grafana evoluiu para se tornar uma plataforma robusta e adaptável, capaz de trabalhar com múltiplas fontes de dados e facilitando a visualização unificada de logs, métricas e traços.
A problemática inicial enfrentada pelo Grafana centrava-se na complexidade das ferramentas de monitoramento da época, que dificultavam a rápida identificação e resolução de problemas em ambientes baseados em microserviços.
A solução proposta por Ödegaard, através da criação de uma interface gráfica limpa, interativa e altamente configurável, não apenas simplificou esses processos, mas também democratizou o acesso à observabilidade avançada para uma vasta comunidade de desenvolvedores.
Com a adoção do modelo de plug-ins e a filosofia de "grande tenda" do Grafana, a ferramenta permitiu a integração de cerca de 150 fontes de dados diferentes, oferecendo aos usuários a liberdade de escolher como e quais dados visualizar sem se prender a soluções proprietárias.
Esta abordagem aberta e inclusiva foi fundamental para o crescimento exponencial do uso do Grafana, culminando em uma comunidade ativa com mais de 20 milhões de usuários até a data presente
Esse é um número respeitável sob qualquer base de comparação, ainda mais quando se considera o "público-alvo" de usuários desse tipo de solução (um público bem diferente das plataformas de streaming ou outros serviços digitais de massa).
Ao alcançar a marca de 20 milhões de usuários, o Grafana solidificou sua posição como uma ferramenta fundamental no campo da observabilidade.
A popularidade do Grafana não se limita apenas ao monitoramento de aplicações e infraestruturas, pois suas capacidades de visualização e a facilidade de integrar dados variados ampliaram seu uso para projetos estudantis, jogos eletrônicos e até no centro de controle da SpaceX.
Este marco reflete não apenas a utilidade da ferramenta, mas também a aceitação e a confiança que a comunidade global de desenvolvedores deposita no Grafana, reforçada por parcerias estratégicas com grandes provedores de nuvem como AWS, Microsoft Azure e Google Cloud.
Essas colaborações têm fortalecido a presença do Grafana no mercado, oferecendo aos usuários soluções ainda mais integradas e acessíveis através de plataformas de nuvem populares.
No cenário atual, falhas, degradações de desempenho ou indisponibilidades não são apenas problemas técnicos, são obstáculos diretos ao sucesso empresarial.
Com a paciência do usuário diminuindo e a dependência de sistemas digitais aumentando, a observabilidade se torna essencial.
Ela permite que as empresas não apenas detectem e resolvam incidentes rapidamente, mas também antecipem falhas antes que elas ocorram.
Esta necessidade transforma a observabilidade de uma simples ferramenta de monitoramento para uma função crítica que sustenta a continuidade dos negócios, a otimização de desempenho e a melhoria contínua.
Em uma era onde o digital é a espinha dorsal das operações empresariais, a disciplina de observabilidade, juntamente com as capacidades de Platform Engineering e Engenharia de
Confiabilidade do Site (SRE), emergiu como uma peça central para garantir a eficiência e a robustez dos serviços de TI.
Essa evolução reflete uma mudança de paradigma nas prioridades organizacionais, onde a capacidade de observar, entender e reagir a problemas em ambientes de TI tornou-se uma exigência incontestável, não mais um luxo.
A integração da observabilidade com as práticas de SRE e Platform Engineering cria um ecossistema onde a estabilidade e a eficiência são mantidas através de uma compreensão detalhada e contínua dos sistemas.
SRE utiliza observabilidade para garantir que os acordos de nível de serviço (SLAs) sejam cumpridos e que as metas de nível de serviço (SLOs) sejam um reflexo preciso da experiência do usuário final.
Já a Engenharia de Plataforma utiliza esses insights para construir e manter infraestruturas que não apenas suportam as cargas de trabalho atuais, mas são escaláveis e flexíveis para o futuro.
TI também é cultura e a analogia com Sócrates — "quanto mais sei, mais sei que nada sei" — é particularmente pertinente para a observabilidade.
Este princípio socrático ressoa na humildade necessária para gerenciar sistemas complexos.
A cada problema resolvido, novas perguntas surgem e a cada incidente monitorado, descobre-se novas camadas de complexidade e pontos a serem observados.
Assim, a observabilidade não é apenas sobre coletar dados, mas sobre interpretar esses dados de maneira que continuamente expanda nosso entendimento e capacidade de resposta. Isso incentiva uma cultura de questionamento constante, aprendizado contínuo e inovação.
A fim de prover alguma base teórica sobre o tema de SRE, a seguir é apresentado o conteúdo resumido oferecido pelo CIO Codex Framework sobre esse tema.
Reliability Engineering, ou Engenharia de Confiabilidade, representa um pilar fundamental na estrutura operacional de TI, que se dedica a assegurar que sistemas e serviços tecnológicos sejam robustos, resilientes e confiáveis.
A confiabilidade é a pedra angular que sustenta a operacionalização contínua e eficaz dos sistemas tecnológicos, essencial para a manutenção da continuidade dos negócios e para a satisfação do cliente.
Com base nos princípios do Site Reliability Engineering (SRE) e do DevSecOps, a Engenharia de Confiabilidade integra práticas de desenvolvimento e operações com um enfoque especial na segurança e na qualidade de longo prazo.
O SRE é uma abordagem que coloca ênfase na automação de processos operacionais e na criação de sistemas que podem escalar e se recuperar de falhas automaticamente, minimizando a necessidade de intervenção manual e maximizando a disponibilidade.
Por outro lado, o DevSecOps amplia o foco do DevOps, incorporando considerações de segurança desde o início do ciclo de vida de desenvolvimento de software, garantindo que as práticas de segurança sejam uma responsabilidade compartilhada e integrada ao longo de todo o processo.
Esta abordagem busca criar uma cultura onde a segurança é considerada tão fundamental quanto a entrega e a qualidade.
Entre os conceitos e características chave de Reliability Engineering se destacam:
Automação e Auto recuperação
Desenvolver sistemas que não apenas detectam e respondem a incidentes sem intervenção humana, mas que também aprendem e se adaptam a novas ameaças e mudanças no ambiente.
Design de Falhas
Adotar uma mentalidade que assume que falhas acontecerão e projetar sistemas de maneira que suas consequências sejam minimizadas.
Testes de Carga e Simulações
Implementar testes rigorosos que simulam condições extremas e cenários de falhas para garantir que os sistemas possam lidar com condições adversas.
Gerenciamento de Incidentes
Estabelecer processos robustos para gerenciamento de incidentes, incluindo a identificação rápida, resolução, análise pós-incidente e ações de melhoria contínua.
Monitoramento e Observabilidade
Criar sistemas de monitoramento que fornecem insights em tempo real sobre o desempenho dos sistemas e permitem uma resposta rápida e informada a problemas.
Balanceamento entre Velocidade e Estabilidade
Encontrar o equilíbrio certo entre inovação rápida e a estabilidade necessária para evitar a degradação do serviço.
Cultura de Aprendizagem e Melhoria Contínua
Promover um ambiente onde o aprendizado com falhas e quase falhas é incentivado, levando a melhorias consistentes nos sistemas e práticas.
Esses conceitos e metodologias ajudam as organizações a evoluir de uma abordagem reativa para uma proativa em relação à confiabilidade.
A integração entre SRE e DevSecOps significa que a confiabilidade não é apenas um objetivo a ser alcançado, mas um processo contínuo de melhoramento e adaptação, mantendo a organização resiliente frente aos desafios constantes da tecnologia e do mercado.
Platform Engineering é um conceito inovador na camada Organizational que reflete a evolução do desenvolvimento de sistemas e operações de TI.
Este modelo redefine as responsabilidades das equipes de desenvolvimento, ampliando seu escopo para incluir não só a criação, mas também a operação contínua dos sistemas em ambientes de produção.
O conteúdo aborda a abordagem de Platform Engineering e como ela promove uma mentalidade de "você constrói, você opera", incentivando os desenvolvedores a considerarem aspectos operacionais desde o início do ciclo de vida do desenvolvimento.
A integração das responsabilidades de desenvolvimento e operação sob o mesmo teto visa a otimização do desempenho dos sistemas e a maximização da qualidade do serviço.
Este conteúdo explora as práticas de Platform Engineering, destacando como esta abordagem pode melhorar a colaboração entre as equipes, aumentar a eficiência operacional e garantir a implementação de soluções mais robustas e confiáveis.
É dada atenção especial às metodologias e ferramentas que suportam o Platform Engineering, como automação de infraestrutura, integração contínua, entrega contínua (CI/CD) e monitoramento em tempo real.
A discussão inclui como essas práticas são essenciais para a criação de plataformas que são resilientes, escaláveis e que podem ser mantidas com eficiência a longo prazo.
O conteúdo também enfrenta os desafios associados à adoção do Platform Engineering, como a necessidade de uma mudança cultural que abrace a propriedade integral do ciclo de vida do produto e o ajuste nos processos tradicionais de desenvolvimento e operações de TI.
São apresentadas estratégias para superar a resistência à mudança, gerenciar a complexidade e educar as equipes para uma nova forma de trabalhar.
A engenharia de plataforma, à primeira vista, pode parecer uma repaginação das práticas estabelecidas de DevSecOps.
O grande diferencial do Platform Engineering está na ideia de acelerar o ciclo de desenvolvimento e segurança operacional através de uma estrutura mais organizada e eficiente, bastante inspirada nos conceitos do "Team Topologies".
Esta abordagem foca em aumentar a produtividade e a qualidade por meio da especialização dos times.
Times dedicados ao desenvolvimento de software são apoiados por equipes de plataforma, que são especialistas em fornecer os componentes estruturais necessários, como arquitetura e pipelines automatizados de DevSecOps.
Este modelo é essencialmente uma extensão lógica do que já é praticado em DevSecOps, onde a segurança é integrada ao ciclo de vida do desenvolvimento de software desde o início.
O que a engenharia de plataforma introduz é uma camada adicional de especialização e suporte, permitindo que as equipes de desenvolvimento se concentrem mais na lógica de negócios e menos na infraestrutura e na conformidade de segurança, que são gerenciadas por uma equipe dedicada.
Sob a perspectiva de escala, a engenharia de plataforma faz muito sentido.
Ela oferece uma maneira estruturada de lidar com as crescentes demandas por software em um ambiente empresarial cada vez mais dependente de tecnologia.
Ao criar equipes especializadas que podem focar exclusivamente em suas áreas de expertise, reduzimos o gargalo que frequentemente ocorre quando os desenvolvedores precisam navegar entre as complexidades da infraestrutura e da segurança.
Além disso, a engenharia de plataforma pode aumentar a agilidade das organizações ao permitir uma entrega mais rápida e eficiente de software.
A integração e entrega contínuas (CI/CD), fundamentais para o DevOps e DevSecOps, são aprimoradas sob o modelo de engenharia de plataforma, pois as ferramentas e processos são padronizados e otimizados por equipes que entendem profundamente as nuances e requisitos técnicos.
A adoção geral de práticas de engenharia de plataforma no mercado parece não só sensata, mas inevitável.
Empresas que buscam escalar suas operações de desenvolvimento sem sacrificar a qualidade ou a segurança verão na engenharia de plataforma uma solução atraente.
Isso se alinha com a tendência geral de especialização e divisão de trabalho, onde equipes altamente focadas podem atingir objetivos específicos com maior eficiência e eficácia.
Além disso, em um mercado que valoriza a rapidez e a adaptabilidade, a capacidade de responder rapidamente às mudanças, ao mesmo tempo em que se mantém a integridade e a segurança do sistema, é mais crucial do que nunca.
A engenharia de plataforma facilita esta dinâmica ao reduzir a carga sobre as equipes de desenvolvimento, permitindo-lhes manter o foco na inovação e na criação de valor.
Por fim, este conteúdo destaca a importância de estabelecer métricas de sucesso claras para as iniciativas de Platform Engineering, tais como a estabilidade do sistema, a frequência de lançamentos bem-sucedidos e a satisfação do usuário final.
O objetivo é prover uma visão clara sobre como o Platform Engineering pode ser um elemento transformador no modelo operacional de TI, entregando sistemas e plataformas que não apenas atendem às necessidades atuais, mas são projetados para a adaptabilidade e sucesso futuros.
Na prática, a engenharia de plataforma (Platform Engineering) representa um divisor de águas na maneira como as organizações desenvolvem e operam sistemas.
Sua premissa central – "you build it, you run it" – redefine a responsabilidade dos times de desenvolvimento, atribuindo-lhes o dever de operar e sustentar os sistemas que criam.
Essa abordagem traz benefícios claros: maior agilidade, confiabilidade operacional e alinhamento com as demandas de negócio.
Plataformas como Alicerces da Inovação
A prática de Platform Engineering destaca a criação de plataformas de autoatendimento como um dos pilares fundamentais.
Essas plataformas oferecem ferramentas, pipelines automatizados e serviços padronizados que permitem aos desenvolvedores provisionarem recursos e lançar aplicações sem depender de outras equipes.
Por exemplo, um catálogo de serviços em nuvem que possibilita a criação de ambientes de teste em minutos, sem burocracia, reduz drasticamente o tempo de espera e acelera o desenvolvimento.
Isso não só promove eficiência como também melhora a experiência dos desenvolvedores, permitindo que eles se concentrem em entregar valor ao negócio.
Transformação Operacional na Prática
Implementar Platform Engineering requer a adoção de práticas modernas e ferramentas robustas. Entre os elementos-chave da transformação prática estão:
Essas práticas criam um ciclo de desenvolvimento mais eficiente e resiliente, transformando a TI em um parceiro estratégico confiável para o negócio.
Cultura de Colaboração: A Base do Sucesso
Na prática, a engenharia de plataforma só é bem-sucedida quando sustentada por uma cultura colaborativa.
Desenvolvedores, operadores, especialistas em segurança e stakeholders de negócios precisam trabalhar juntos para garantir que os sistemas atendam às necessidades do negócio enquanto mantêm altos padrões de qualidade e segurança.
Um exemplo prático dessa colaboração é a criação de times multifuncionais inspirados no conceito de "Team Topologies".
Equipes de plataforma, como "enabling teams", oferecem suporte e capacitação para que as equipes de desenvolvimento possam operar de forma autônoma, mas dentro de padrões e diretrizes estabelecidos.
Superando Desafios no Mundo Real
Embora a engenharia de plataforma traga inúmeros benefícios, sua implementação não está isenta de desafios.
Entre os mais comuns estão:
Uma estratégia prática para lidar com esses desafios é a adoção de indicadores de maturidade que avaliem continuamente o progresso, identificando lacunas e oportunidades de melhoria.
Indicadores de Sucesso na Prática
O sucesso da engenharia de plataforma deve ser medido por métricas claras que reflitam seu impacto operacional e estratégico. Exemplos incluem:
Esses indicadores permitem que as organizações monitorem o impacto real da engenharia de plataforma e ajustem continuamente suas estratégias.
Criando o Futuro com Platform Engineering
A prática de Platform Engineering está pavimentando o caminho para um futuro em que as operações de TI são mais ágeis, resilientes e alinhadas às demandas de negócios.
Ao adotar essa abordagem, as empresas não só aumentam sua eficiência operacional, mas também habilitam seus desenvolvedores a inovar de forma mais rápida e consistente.
Com plataformas robustas, uma cultura de colaboração e ferramentas modernas, a engenharia de plataforma posiciona as organizações para navegar com sucesso no cenário digital acelerado e competitivo de hoje.
O conceito de Platform Engineering é uma disciplina emergente no domínio da Tecnologia da Informação, reconhecendo a crescente complexidade dos sistemas e a necessidade de uma abordagem holística que abrange tanto a criação quanto a operação de sistemas em ambientes de produção.
A seguir é explorada a evolução cronológica do Platform Engineering, destacando como essa abordagem tem sido desenvolvida e ajustada ao longo do tempo para enfrentar os desafios de um ambiente de negócios em constante evolução.
1) – Início e Evolução do Platform Engineering (Anos 2000 – 2010)
2) – Expansão e Maturidade do Platform Engineering (Anos 2010 – 2020)
3) – Implementação e Consolidação do Platform Engineering (2020 – Presente)
4) – Reflexões e Desafios Futuros do Platform Engineering
Platform Engineering está redefinindo o ecossistema de TI, pois ao alinhar de perto a criação e operação de sistemas, as organizações ganham em agilidade, qualidade e desempenho.
Com o desenvolvedor no centro desta transformação, a prática está se tornando um componente vital para empresas que buscam inovar e competir em um mundo digital acelerado.
As preocupações operacionais agora são uma consideração primária e não uma reflexão tardia, garantindo que a tecnologia não apenas atenda às necessidades atuais, mas também seja sustentável e resiliente no longo prazo.
A Engenharia de Plataforma é uma disciplina emergente que responde à crescente complexidade dos sistemas modernos e à necessidade de alinhar criação e operação de software em um único ciclo contínuo.
Seu princípio central "you build it, you run it" incentiva desenvolvedores a assumirem também a responsabilidade operacional, promovendo maior consciência sobre as implicações de design e código em ambientes de produção.
Essa abordagem redefine a forma como as equipes de TI trabalham, unindo desenvolvimento e operações em torno de plataformas que oferecem autoatendimento, padronização e automação, ao mesmo tempo em que preservam governança, segurança e eficiência.
Mais do que um conjunto de ferramentas, a Engenharia de Plataforma é uma estratégia organizacional que possibilita maior agilidade, resiliência e qualidade, colocando o desenvolvedor no centro da transformação digital.
A Platform Engineering está redefinindo o ecossistema de TI, uma vez que ao integrar criação e operação em torno de plataformas robustas e autosserviço, proporciona agilidade, eficiência, resiliência e sustentabilidade no longo prazo.
Para empresas que buscam competir em um mundo digital acelerado, ela se tornou uma disciplina vital, alinhando inovação, governança e responsabilidade compartilhada.
A seguir, estão os principais conceitos e características que fundamentam o Platform Engineering.
Definição e Propósito
Engenharia de Plataforma é a prática de desenvolver e manter uma base comum de código, ferramentas e processos que podem ser reutilizados por várias equipes de desenvolvimento. O objetivo é reduzir redundância, otimizar recursos e facilitar a escalabilidade das aplicações.
Componentes Reutilizáveis e Autoatendimento
Um dos pilares do modelo é a criação de bibliotecas, APIs, microserviços e interfaces que possam ser reutilizados em diferentes projetos. As plataformas de autoatendimento permitem que desenvolvedores provisionem recursos e configurem ambientes sem depender de suporte operacional, aumentando autonomia e velocidade.
Infraestrutura como Código (IaC)
A prática de gerenciar infraestrutura por meio de código substitui processos manuais, trazendo precisão, rastreabilidade e automação. O IaC suporta pipelines de CI/CD, permitindo que mudanças em infraestrutura sejam versionadas, testadas e entregues com a mesma fluidez que o código de aplicação.
Padronização e Governança
A Engenharia de Plataforma define padrões claros para desenvolvimento, segurança, monitoramento e operações. Esses padrões garantem consistência e qualidade em toda a organização. A governança assegura que tais práticas sejam aplicadas, equilibrando inovação com conformidade regulatória e política interna.
Cultura de DevOps e Colaboração
Platform Engineering fortalece a cultura de DevOps, unindo desenvolvedores, operadores e stakeholders em torno de uma colaboração contínua. Ferramentas e práticas integradas ao ciclo de vida do software facilitam entregas rápidas, aprendizado contínuo e resolução eficiente de problemas.
Monitoramento Contínuo e Automação
A observabilidade e o monitoramento contínuo são fundamentais para manter a saúde da plataforma. Aliados à automação, permitem detectar e corrigir falhas rapidamente, além de antecipar riscos e prevenir incidentes antes que afetem o ambiente produtivo.
Segurança Integrada
Na Engenharia de Plataforma, a segurança é incorporada desde o início do ciclo de desenvolvimento. Políticas automatizadas, testes contínuos e práticas de DevSecOps asseguram que a proteção dos sistemas seja tratada como parte essencial do processo, e não como uma etapa posterior.
Em retrospecto, a trajetória do Grafana é um reflexo claro da evolução das necessidades e da complexidade dos ambientes de TI modernos.
A ferramenta não apenas facilitou a observabilidade, mas também aprimorou a maneira como as equipes de desenvolvimento e operações interagem com os dados.
O compromisso com uma arquitetura aberta e expansível garantiu que o Grafana permanecesse relevante em um mercado em constante mudança.
Na minha perspectiva, o sucesso do Grafana reitera a importância de soluções que priorizam a flexibilidade, a adaptabilidade e a inclusão de contribuições da comunidade.
Tais princípios são essenciais para o desenvolvimento de tecnologias que não apenas respondem às exigências atuais, mas também se adaptam às necessidades futuras.
Por fim, a história do Grafana nos ensina que a inovação contínua, sustentada por uma visão clara e um compromisso com a abertura, é a chave para transformar desafios complexos em oportunidades de crescimento e melhoria.
Por sua vez, adotar a observabilidade, juntamente com práticas de SRE e Engenharia de Plataforma, dentro de uma filosofia "socrática", não é apenas adotar uma ferramenta ou técnica, mas abraçar uma cultura de constante questionamento e autoaperfeiçoamento.
Este enfoque filosófico permite que as organizações não apenas enfrentem os desafios atuais, mas também se preparem para as incertezas futuras. Assim, a observabilidade transcende sua função original e se torna uma pedra angular para o desenvolvimento de uma infraestrutura de TI resiliente, adaptativa e profundamente alinhada com as necessidades de negócio.
Portanto, mais do que nunca, é vital que as empresas cultivem uma profunda capacidade de observação e reflexão, garantindo não apenas a performance técnica, mas também a evolução contínua e consciente de suas práticas tecnológicas e culturais.
E pensar que eu iniciei a minha carreira em tecnologia programando na plataforma Mainframe e ouvindo desde então que ela estava prestes a morrer!
Eu lembro como se fosse ontem meu início da carreira na área, de forma totalmente despretensiosa a partir de uma bolsa de estudos em um curso de 2 meses de Cobol, CICS, JCL e DB2, quando eu estava no penúltimo semestre da faculdade.
Na época meus colegas ficaram intrigados com a "loucura" de gastar tempo com uma tecnologia que desde então já estava "morta ou prestes a morrer".
Passados pouco mais de 20 anos, sou muito grato por todas as oportunidades de crescimento na carreira que tive desde esse primeiro passo.
Nunca saberei como teria sido se tivesse seguido algum outro caminho, mas sou bastante feliz com todas as experiências de vida que tive desde então.
Não creio que a plataforma mainframe seja hoje a primeira e muito menos a única opção quando se pensa em iniciar um serviço do zero (o crescimento vertiginoso da cloud - primordialmente em baixa plataforma - mostra isso), mas certamente ainda tem um papel bastante relevante em muitos segmentos.
E ainda deve se manter relevante por um bom tempo.
Há algum tempo comentei que é bem possível que ela siga viva (mesmo que não com a mesma relevância) até mesmo quando chegar a minha aposentadoria em um futuro (espero eu que de longo prazo).
Afinal, Já se foram 20 anos e ela segue com a "morte anunciada", mas ao mesmo tempo com exemplos empíricos que mostram que isso ainda deve levar longos anos.
Mas será que sair da plataforma mainframe é impossível?
Como basicamente tudo em tecnologia, desde que se tenha à disposição tempo e dinheiro, é difícil dizer que algo seja impossível.
Mas para ter uma visão mais prática e baseada em casos reais, é sempre legal ver casos como esse da Allianz, onde se confirma que basicamente tudo é possível em IT.
Para quem quiser mais detalhes, abaixo o link da matéria da CIO Online:
https://www.cio.com/article/479654/examining-allianz-technologys-decision-to-replatform.html
É claro que cada caso é um caso e dessa forma cada organização tem que fazer suas contas e concluir se faz sentido ou não mudar de plataforma, ou mesmo para quais aplicações isso faz algum sentido.
Em meados de 2019, a Allianz Technology decidiu migrar seu Sistema de Negócios Allianz (ABS), que inclui aplicações de TI centrais e sua base de dados, de mainframes para servidores x86 padronizados com sistemas operacionais Linux.
O projeto, intitulado "ABS Goes Linux", representou uma iniciativa pioneira no setor de seguros, marcada pelo alto grau de complexidade e risco.
A necessidade dessa migração surgiu da incapacidade dos mainframes em escalar adequadamente e suportar inovações, além de uma dificuldade em integrar novas plataformas ou linguagens de programação.
Com a transição para o Linux, esperava-se uma integração mais fluida de aplicações nativas da nuvem e um desenvolvimento ágil, reduzindo a dependência de fornecedores e aumentando a capacitação técnica da TI.
Durante a migração, que foi finalizada na Páscoa de 2022, a Allianz enfrentou vários desafios, incluindo a necessidade de migrar um dos maiores bancos de dados baseados em Linux DB2 como um todo, o que exigiu uma abordagem iterativa e colaborativa com os fornecedores para ajustar seus produtos às necessidades específicas do projeto.
Além disso, a mudança requereu a reorganização da base de dados e ajustes de infraestrutura para suportar o novo sistema, culminando em uma migração técnica intensiva durante um fim de semana prolongado.
A migração do ABS para o Linux não foi apenas uma mudança de tecnologia, mas uma transformação abrangente que envolveu revisão de processos, gestão de mudanças e realinhamento estratégico.
Projetos como o "ABS Goes Linux" são vitais para manter a competitividade e responder às demandas de um mercado em evolução.
Esta iniciativa não só aumentou a eficiência operacional da Allianz, mas também fortaleceu a confiança dos stakeholders internos ao demonstrar melhorias tangíveis em termos de desempenho e capacidade de inovação.
Projetos de migração de grande escala são complexos e exigem um comprometimento significativo em termos de recursos e gestão.
No entanto, os benefícios a longo prazo, como redução de custos operacionais e maior flexibilidade tecnológica, justificam esses esforços.
A experiência da Allianz serve como um exemplo valioso para outras organizações que contemplam transformações tecnológicas similares, mostrando que, com planejamento adequado e envolvimento integral da equipe, é possível superar os desafios e atingir resultados excepcionais.
Li muita coisa sobre a plataforma mainframe z17 trouxe uma série de avanços enquanto interoperabilidade com cloud pública e privada, além do processamento de AI.
Para muitos casos ela deve seguir sendo adequada, mas ainda assim, sigo igualmente ouvindo que os custos da plataforma mainframe seguem mais altos do que o análogo em outras plataformas (que por sua vez alcançaram alto nível de throughput e disponibilidade)
Daí essa proliferação de casos de migrações do mainframe para outras plataformas.
Creio que essa vantagem financeira tende a ser ainda mais gritante com a ascensão vertiginosa do mundo cloud e da explosão de oferta de provedores e serviços.
E esse novo mercado de cloud está cheio de empresas gigantescas interessadas em conquistar mercado e assim oferecendo deals muito interessantes para contratos de grandes workloads sabidamente "perenes" e recorrentes no longo prazo (que são os casos típicos de quem processa grandes volumes em mainframe).
Como será que se dará o "equilíbrio" do mercado nesse sentido?
Será que a IBM vai baixar seus preços?
Será que ela vai conseguir estancar esses casos de migrações?
Na verdade, qual será a taxa de crescimento ou redução dos clientes mainframe?
Estão realmente reduzindo ou simplesmente crescendo menos que o resto do mercado?
Enfim, gostaria de ter uma visão sobre esses números, apenas por curiosidade mesmo.
Mas vale ponderar que trilhar esse caminho de saída não é um passeio no parque.
A dificuldade cresce conforme a complexidade da plataforma/arquitetura de aplicações, especialmente nas grandes empresas com muito processamento, muitas aplicações, muitas integrações e acoplamentos profundos entre si desenvolvidos ao longo de muitos anos (as vezes décadas).
Muitas dessas integrações, acoplamentos e suas regras de negócio possivelmente existem sem o conhecimento de mais nenhuma pessoa ou documentação nas organizações (a vida como ela é) e conforme se avança no processo de migração e vai se descobrindo essa complexidade oculta ou desconhecida, a realidade vai se descolando do business case original.
Ao mesmo tempo, qualquer um que coloca workloads na cloud percebe rapidamente que os custos de operação podem sair facilmente de controle se não houver um rígido controle e visão crítica.
E por fim, o nível de serviço, que é para muitas indústrias um fator chave.
Afinal, não é uma decisão fácil virar a chave e sair de algo que se sabe que está funcionando e com os serviços de pé e ir para algo que muito provavelmente necessitará de algum fine tuning até operar no mesmo nível de disponibilidade e performance (algo natural em migrações assim).
E essa visão de que na vida real sair do Mainframe não é um passeio no parque é reforçada pelo case apresentado na matéria.
E tenho certeza de que tiveram bem mais surpresas e desafios que o apresentado resumidamente no artigo.
Os números macro mostram isso:
"The core project team consisted of around 500 employees while around 3,000 people worked at times in various phases, and the budget was a low, three-figure million euro amount."
Da mesma forma, esse tipo de iniciativa precisa do buy-in absoluto da organização (tanto IT quanto o Business), seja pelo tamanho do impacto na operação, seja na dedicação geral de múltiplos times e pessoas envolvidas, seja no sangue frio e disciplina para entender que o retorno sobre o investimento só se dará ao longo de alguns anos:
"Bearing that in mind, the project plan is for it to pay for itself after three to four years."
Mas quando olho a evolução recente do universo Cloud cada vez mais maduro, parece que dessa vez o Mainframe finalmente encontrou um concorrente a altura.
Que o digam cases reais de avanços que vão sendo divulgados aqui mesmo no Brasil pelo Santander e Itaú, além do caso da Allianz comentado na matéria.
Em paralelo se vê avanços (acho que da própria IBM) em utilizar Gen AI na migração de soluções Cobol para Java. Microsoft e Amazon devem possuir algo análogo.
Os ataques de disrupção estão vindo por todos os lados.
Acho que nunca tantos fatores se uniram em um mesmo momento de forma a promover e facilitar a transformação do Cobol para outras plataformas!
Como comentei há algum tempo, não sei se esse é o "Ragnarok" do Mainframe, mas vale acompanhar os próximos capítulos dessa história nos próximos anos.
Penso que é de se admirar a incrível flexibilidade e adaptabilidade que a plataforma Mainframe vem demonstrando ao longo de mais de 60 anos de vida.
Uma tecnologia que nasceu em uma época de cartões perfurados, fitas magnéticas, terminais centralizados e processamento em lote continua, ainda hoje, presente no centro de muitas das operações mais críticas do mundo corporativo.
Mais do que isso, ela vem sendo modernizada para dialogar com Cloud, APIs, DevOps, automação, segurança avançada, criptografia pós-quântica e, mais recentemente, Artificial Intelligence.
Também me parece interessante imaginar como seria a competição entre plataformas em uma realidade paralela na qual os custos do mundo Mainframe fossem mais baixos.
Talvez a narrativa dominante sobre substituição, migração e modernização tivesse sido diferente. Talvez muitas empresas tivessem colocado menos energia em tentar retirar workloads críticos dessa plataforma.
Talvez o Mainframe tivesse sido percebido não como um legado caro a ser reduzido, mas como uma plataforma premium, extremamente confiável, altamente especializada e naturalmente adequada para determinados tipos de carga de trabalho.
Ao longo dessas décadas, o Mainframe já enfrentou praticamente todas as grandes ondas tecnológicas: minicomputadores, arquitetura cliente-servidor, Unix, servidores x86, virtualização, web, SOA, Linux, cloud computing, containers, APIs, microsserviços, plataformas digitais e, agora, AI.
Em muitos momentos, foi anunciada a sua obsolescência. Em outros, foi tratado como uma tecnologia do passado. Porém, em vez de desaparecer, foi se reposicionando.
Sua permanência não decorreu de nostalgia tecnológica, mas de uma combinação muito objetiva de fatores: escalabilidade vertical, confiabilidade operacional, segurança, governança, capacidade transacional, compatibilidade histórica e uma engenharia construída para workloads de missão crítica.
A história do Mainframe, portanto, não é apenas a história de uma máquina. É a história de uma arquitetura. É a história de uma forma de pensar computação empresarial. É a história de como algumas plataformas sobrevivem não porque são as mais populares, mas porque resolvem problemas que poucas outras conseguem resolver com o mesmo nível de previsibilidade.
A origem moderna do Mainframe costuma ser associada ao IBM System/360, anunciado em 7 de abril de 1964. O System/360 foi um divisor de águas porque não representava apenas mais um computador dentro de uma linha de produtos.
Ele representava uma família compatível de sistemas, criada para cobrir diferentes tamanhos, capacidades e faixas de preço, permitindo que uma organização crescesse sem precisar reescrever completamente seus programas a cada nova evolução de hardware.
A própria IBM descreve o System/360 como o sistema que inaugurou uma nova era de compatibilidade, na qual computadores passaram a ser pensados como plataformas, e não como coleções isoladas de componentes.
Antes desse momento, o mercado de computadores empresariais era marcado por fragmentação. Máquinas diferentes tinham arquiteturas diferentes, instruções diferentes, periféricos diferentes e modelos de programação diferentes.
Uma empresa que adquiria um computador para uma finalidade específica, como contabilidade, processamento científico ou folha de pagamento, frequentemente ficava presa àquele ambiente.
A expansão não era simples. A migração não era fluida. A evolução tecnológica podia significar um redesenho completo das aplicações.
O System/360 atacou diretamente esse problema. A proposta era ambiciosa: criar uma linha de computadores compatíveis entre si, que pudesse atender desde necessidades menores até grandes operações corporativas.
Essa compatibilidade permitia que programas fossem preservados à medida que a empresa evoluía para modelos mais potentes. O impacto foi tão relevante que o System/360 passou a ser lembrado como uma das grandes apostas empresariais da história da tecnologia, frequentemente descrito como um movimento de altíssimo risco para a IBM, mas também como uma das decisões mais transformadoras da indústria.
Esse é um ponto essencial para entender a longevidade do Mainframe. Desde o início, sua proposta não era apenas processar dados.
Sua proposta era proteger investimentos, preservar continuidade e criar uma base tecnológica capaz de evoluir ao longo do tempo.
Em outras palavras, o Mainframe já nasceu com uma preocupação que continua absolutamente atual: compatibilidade evolutiva.
Nas décadas de 1960 e 1970, a computação corporativa era naturalmente centralizada. Os computadores eram grandes, caros, complexos e operados por equipes especializadas. O acesso era feito por cartões perfurados, terminais ou processos em lote.
O usuário final não tinha a relação direta com a tecnologia que passou a existir décadas depois com o computador pessoal, a internet e os smartphones.
Nesse contexto, o Mainframe se consolidou como o grande centro nervoso das corporações.
Bancos, seguradoras, governos, companhias aéreas, empresas de telecomunicações, indústrias e grandes varejistas passaram a depender desses sistemas para processar transações, registrar operações, calcular saldos, emitir faturas, controlar estoques, liquidar pagamentos e manter registros oficiais.
A palavra centralização, muitas vezes vista hoje com certa desconfiança em debates sobre arquitetura, naquele momento era uma virtude.
Centralizar significava controlar. Significava garantir integridade. Significava proteger dados. Significava permitir que grandes volumes de processamento fossem executados com disciplina operacional.
O Mainframe cresceu exatamente nesse ambiente. Ele foi desenhado para ser compartilhado por muitos usuários, muitos programas e muitos processos ao mesmo tempo.
O conceito de multiprogramação, o uso eficiente de recursos computacionais, a priorização de workloads, a administração rigorosa de memória, o controle de acesso e a resiliência operacional passaram a fazer parte de sua identidade técnica.
A computação empresarial nasceu, em grande medida, com essa lógica. Antes da cultura digital contemporânea, antes da computação distribuída e antes da cloud, já existia uma preocupação muito forte com disponibilidade, segurança, performance, eficiência e governança.
O Mainframe foi uma das plataformas que mais incorporou esses princípios.
Na década de 1970, o System/370 sucedeu o System/360 e aprofundou vários fundamentos que seriam essenciais para a evolução da plataforma. Um dos marcos mais importantes desse período foi o avanço da virtualização.
Embora muitos associem virtualização ao mundo x86 e aos data centers modernos, a ideia de compartilhar recursos físicos de forma isolada, controlada e eficiente já era explorada há muito tempo no ambiente Mainframe.
Esse ponto costuma ser subestimado. Muitas práticas que posteriormente se tornaram populares na infraestrutura distribuída já eram conhecidas no mundo Mainframe em formas mais maduras e rigorosas.
Isolamento de workloads, particionamento lógico, gestão centralizada de capacidade, alocação dinâmica de recursos e alta utilização do hardware fazem parte da tradição técnica dessa plataforma.
Enquanto o mundo distribuído muitas vezes cresceu por meio da proliferação de servidores, o Mainframe cresceu por meio da consolidação.
Enquanto a infraestrutura aberta, em muitos casos, avançou adicionando mais máquinas, mais instâncias, mais appliances e mais camadas, o Mainframe evoluiu explorando densidade, controle e otimização interna.
Essa diferença moldou duas culturas. De um lado, uma cultura distribuída, orientada à expansão horizontal, à especialização de componentes e à substituição relativamente frequente de tecnologia.
De outro, uma cultura Mainframe, orientada à estabilidade, à continuidade, à máxima utilização de recursos e à preservação de investimentos de longo prazo.
Nenhuma dessas culturas é universalmente superior. Ambas têm virtudes e limitações, mas é importante reconhecer que o Mainframe não sobreviveu por estar parado.
Ele sobreviveu porque evoluiu dentro de uma lógica própria.
A identidade mais forte do Mainframe foi construída em torno do processamento transacional. Em setores como bancos, cartões, seguros, meios de pagamento, companhias aéreas e governo, a transação é a unidade fundamental da operação.
Uma transferência financeira, uma autorização de cartão, uma reserva aérea, uma atualização de saldo, uma liquidação, uma apólice emitida, uma consulta cadastral ou um pagamento processado não são apenas eventos técnicos. São atos de negócio.
Em ambientes desse tipo, alguns atributos deixam de ser desejáveis e passam a ser mandatórios. A transação precisa ser processada corretamente. O dado precisa permanecer íntegro. A operação precisa ser auditável.
A indisponibilidade precisa ser mínima. A segurança precisa ser robusta. A recuperação precisa ser confiável. A consistência precisa prevalecer mesmo sob volume extremo.
É nesse território que o Mainframe encontrou sua maior relevância. A IBM descreve Mainframes como servidores de dados projetados para processar até 1 trilhão de transações web por dia, com altos níveis de segurança e confiabilidade.
A própria definição contemporânea da plataforma continua ligada a essa noção de processamento massivo, crítico e confiável.
O z/Transaction Processing Facility, por exemplo, é descrito pela IBM como um processador voltado a transações de altíssimo volume em ambientes de tempo real.
Esse tipo de posicionamento mostra que o Mainframe permaneceu fortemente associado a contextos nos quais latência, consistência, throughput e disponibilidade não podem ser tratados como variáveis secundárias.
Essa é uma das razões pelas quais muitas iniciativas de migração integral encontraram dificuldades. Migrar uma aplicação simples é uma coisa.
Migrar um ecossistema transacional crítico, altamente integrado, com décadas de regras de negócio, janelas operacionais restritas, dependências regulatórias, integrações batch, interfaces online, auditoria e volumetria extrema é outra completamente diferente.
Desde muito cedo, o Mainframe enfrentou concorrência. A própria relevância do System/360 atraiu competidores como Burroughs, UNIVAC, NCR, Control Data e Honeywell, grupo que ficou conhecido historicamente como BUNCH.
Posteriormente, novas ondas tecnológicas prometeram reduzir custos, aumentar flexibilidade e descentralizar o processamento.
Na década de 1980, o computador pessoal mudou a relação dos usuários com a tecnologia. A computação deixou de ser algo distante, fechado no data center, e passou a ocupar mesas, departamentos e áreas de negócio.
A partir daí, o Mainframe começou a ser visto por alguns como símbolo de centralização excessiva.
Na década de 1990, a arquitetura cliente-servidor intensificou esse movimento. Aplicações passaram a ser distribuídas entre servidores departamentais e estações de trabalho.
Bancos de dados relacionais em plataformas abertas ganharam força. Sistemas Unix e, mais tarde, Windows Server e Linux passaram a disputar workloads corporativos.
A promessa era clara: mais flexibilidade, menor custo aparente, maior autonomia para as áreas e ciclos de desenvolvimento mais rápidos.
Com a internet, essa pressão aumentou. A web trouxe uma nova escala de interação, novos modelos de negócio, novas arquiteturas e uma estética tecnológica muito diferente daquela associada ao Mainframe.
O mundo passou a falar em aplicações web, servidores de aplicação, middleware, portais, e-commerce, integração por serviços e, depois, APIs.
Mais recentemente, cloud computing reposicionou o debate. O argumento deixou de ser apenas técnico e passou a ser também econômico e estratégico.
Elasticidade, consumo sob demanda, automação, infraestrutura como código, serviços gerenciados, disponibilidade global e inovação acelerada tornaram-se atributos centrais das plataformas cloud.
Em todas essas ondas, o Mainframe foi desafiado. Em todas elas, surgiram previsões de que sua relevância estaria chegando ao fim.
Porém, essas previsões ignoraram um ponto importante: workloads diferentes têm naturezas diferentes.
Nem tudo que pode ser executado fora do Mainframe deve necessariamente ser executado fora dele.
Nem tudo que parece mais barato em um cálculo unitário se mostra mais econômico quando são considerados risco, disponibilidade, reengenharia, volume, integração, segurança, compliance, operação e custo total de transformação.
O custo sempre foi uma das grandes críticas ao Mainframe. Licenciamento de software, MIPS, MSU, consumo de capacidade, contratos de suporte, escassez de profissionais especializados e dependência de fornecedores compõem uma percepção de plataforma cara.
Essa crítica não é irrelevante. Em muitas organizações, o Mainframe representa uma parte expressiva do orçamento de infraestrutura e aplicações.
Mas o debate sobre custo precisa ser tratado com cuidado. O custo de uma plataforma não deve ser avaliado apenas pelo preço unitário de processamento ou armazenamento.
É necessário observar o custo por transação, o custo de indisponibilidade, o custo de risco operacional, o custo de compliance, o custo de migração, o custo de falha, o custo de reescrita de regras de negócio e o custo de perda de conhecimento histórico.
Essa é a razão pela qual tantas iniciativas de substituição acabam sendo mais complexas do que pareciam no business case inicial.
Um workload Mainframe pode parecer caro quando comparado com servidores distribuídos em uma visão simplificada.
Porém, quando se considera a densidade transacional, a disponibilidade, a segurança, a maturidade operacional e a complexidade de recriar décadas de lógica de negócio, o cálculo muda.
Há ainda um aspecto cultural. Muitas organizações passaram anos buscando reduzir o Mainframe por pressão orçamentária, mas sem construir uma compreensão suficientemente granular sobre quais workloads deveriam ser modernizados, quais deveriam ser encapsulados, quais deveriam ser expostos por APIs, quais deveriam ser reescritos e quais deveriam permanecer onde estavam.
Com isso, a modernização muitas vezes foi confundida com substituição.
A modernização mais madura tende a partir de uma premissa diferente. O objetivo não deve ser eliminar uma plataforma por princípio, mas posicionar cada workload no ambiente mais adequado.
Alguns workloads podem ser melhor atendidos em cloud pública. Outros em cloud privada. Outros em plataformas distribuídas tradicionais.
Outros continuam fazendo sentido no Mainframe, especialmente quando criticidade, volume transacional, segurança e continuidade operacional pesam mais do que a moda arquitetural do momento.
Uma das características mais impressionantes do Mainframe é a sua compatibilidade histórica. A capacidade de preservar aplicações, dados, linguagens, modelos operacionais e investimentos por décadas é frequentemente vista como sinal de legado.
Porém, sob outra ótica, essa compatibilidade também pode ser vista como uma forma sofisticada de proteção patrimonial.
Empresas não acumulam apenas código. Elas acumulam conhecimento de negócio. Acumulam regras, exceções, parametrizações, tratamentos regulatórios, integrações, rotinas operacionais e aprendizados que foram incorporados aos sistemas ao longo do tempo.
Em setores regulados, esse conhecimento pode representar uma parte substancial da inteligência operacional da organização.
Quando se fala em modernizar aplicações Mainframe, portanto, não se está falando apenas em converter uma linguagem para outra.
Está se falando em reinterpretar décadas de decisões empresariais. Muitas dessas decisões não estão documentadas. Muitas foram codificadas diretamente em programas COBOL, PL/I, Assembler, JCL, CICS, IMS, DB2 e rotinas batch.
Muitas são conhecidas apenas por profissionais experientes, por operadores, por analistas de sustentação e por usuários que aprenderam a lidar com comportamentos específicos dos sistemas.
Essa é uma das razões pelas quais o Mainframe resiste: não apenas porque o hardware é robusto, mas porque os sistemas que nele vivem carregam conhecimento crítico.
Em muitos casos, o risco de reescrever tudo é maior do que o benefício aparente de sair da plataforma.
Não há como contar a história do Mainframe sem mencionar COBOL. A linguagem, criada em uma época muito anterior à internet, continua sendo utilizada em muitos sistemas críticos. Para alguns, isso é sinal de atraso. Para outros, é prova de uma estabilidade notável.
O problema é que o debate público sobre COBOL costuma ser superficial. É comum que se associe a linguagem a sistemas antigos, difíceis de manter e pouco atrativos para novos profissionais.
Parte dessa crítica é verdadeira. Há, sim, escassez de talentos. Há, sim, dificuldades de documentação. Há, sim, desafios de integração com práticas modernas de desenvolvimento.
Porém, também é verdade que COBOL foi desenhado para processamento de negócios, com legibilidade orientada a regras empresariais, robustez e precisão decimal, atributos relevantes para ambientes financeiros.
A questão central não é demonizar COBOL. A questão é entender como reduzir riscos associados à dependência excessiva de conhecimento antigo, como automatizar testes, como documentar regras, como expor funcionalidades por APIs, como integrar pipelines DevOps, como usar ferramentas de análise estática, como apoiar desenvolvedores com AI e como modernizar a experiência de desenvolvimento sem necessariamente jogar fora sistemas que funcionam.
Nesse sentido, a modernização Mainframe não precisa ser uma decisão binária entre manter tudo como está ou reescrever tudo do zero.
Entre esses extremos, há um amplo conjunto de alternativas: refatoração seletiva, replatforming, encapsulamento, exposição por serviços, extração de dados, decomposição de domínios, integração com eventos, automação de testes, modernização de interfaces, observabilidade e uso de AI para compreensão de código.
Um dos momentos mais relevantes da reinvenção do Mainframe foi a adoção de Linux na plataforma. A chegada do Linux ao Mainframe ajudou a mudar a percepção de que se tratava de um ambiente fechado e isolado.
A possibilidade de executar workloads Linux em uma plataforma com características de Mainframe criou um caminho interessante para consolidação, virtualização e integração com ecossistemas abertos.
Em 2002, por exemplo, a IBM já anunciava iniciativas relacionadas a Mainframes com Linux, em uma tentativa de tornar a plataforma mais acessível e conectada a novos perfis de workloads.
Esse movimento foi importante porque mostrou que o Mainframe poderia abrigar não apenas aplicações tradicionais, mas também componentes modernos baseados em sistemas abertos.
A adoção de Linux também reforçou uma característica que muitos esquecem: o Mainframe é, antes de tudo, uma plataforma de execução. Ele não é apenas z/OS. Ele pode suportar diferentes ambientes e formas de processamento.
Essa flexibilidade permitiu que empresas explorassem consolidação de servidores, workloads open source, aplicações Java, bancos de dados, middleware e integrações modernas em um ambiente com altíssima disponibilidade e forte isolamento.
Esse foi um ponto de inflexão na narrativa. O Mainframe deixou de ser apenas o lugar onde sistemas antigos continuavam rodando e passou a poder ser visto também como uma plataforma capaz de hospedar workloads novos, especialmente quando densidade, segurança e governança eram relevantes.
Com a popularização da internet e, posteriormente, da API Economy, o Mainframe precisou se conectar a um mundo cada vez mais distribuído.
Durante muito tempo, a integração entre sistemas centrais e canais digitais foi feita por camadas intermediárias, barramentos, filas, mensageria, ESBs, adaptadores e serviços.
Essa camada de integração foi fundamental para permitir que bancos, seguradoras, companhias aéreas e governos expusessem funcionalidades críticas para internet banking, mobile banking, portais, aplicativos, parceiros, fintechs, marketplaces e ecossistemas digitais.
Em muitos casos, o usuário final interagia com uma interface moderna, mas a transação final continuava sendo registrada ou autorizada em um sistema Mainframe.
Esse padrão continua relevante. Uma arquitetura digital moderna raramente é composta apenas por sistemas cloud-native.
Ela costuma ser um arranjo híbrido, no qual canais digitais, microsserviços, plataformas de dados, sistemas de integração, motores de decisão, soluções de segurança e sistemas centrais convivem.
O Mainframe, nesse contexto, não precisa ser invisível nem isolado. Ele precisa ser integrado com disciplina arquitetural.
A exposição de capacidades Mainframe por APIs foi uma das formas mais pragmáticas de modernização.
Em vez de remover imediatamente o core, muitas empresas optaram por encapsular funcionalidades, proteger a integridade transacional e acelerar a entrega digital por meio de camadas modernas de integração.
Essa abordagem permite preservar o que é crítico, ao mesmo tempo em que se melhora a experiência do cliente, a velocidade de desenvolvimento e a capacidade de integração com parceiros.
A relação entre Mainframe e Cloud é frequentemente apresentada como competição. De um lado, uma plataforma centralizada, de alto custo, com herança histórica e forte presença em grandes empresas.
De outro, uma plataforma elástica, distribuída, moderna, com consumo sob demanda e ritmo acelerado de inovação.
Essa oposição é compreensível, mas incompleta. Em muitas organizações, a realidade não é Mainframe ou Cloud. A realidade é Mainframe e Cloud.
O ambiente corporativo moderno é híbrido por natureza. Aplicações legadas, SaaS, cloud pública, cloud privada, data centers próprios, edge computing, plataformas de dados, APIs, containers e sistemas centrais coexistem.
A pergunta estratégica correta não deveria ser apenas: como sair do Mainframe? A pergunta mais madura deveria ser: qual é o papel adequado do Mainframe no target architecture da organização?
Em alguns casos, workloads podem e devem migrar. Em outros, a melhor decisão é modernizar no lugar.
Em outros, pode ser interessante desacoplar partes da lógica, mover dados para plataformas analíticas, expor serviços, reduzir dependências, automatizar operação e melhorar a governança de custos.
Em outros ainda, o Mainframe pode continuar sendo o sistema de registro transacional, enquanto a inovação de experiência, analytics e canais digitais ocorre em cloud.
A própria IBM posiciona o z17 como uma plataforma conectada a AI e hybrid cloud, ressaltando integração com dados e aplicações críticas.
Isso indica que a estratégia atual não é tentar proteger o Mainframe por isolamento, mas inseri-lo em uma arquitetura híbrida e moderna.
A segurança sempre foi um dos atributos mais relevantes do Mainframe. Em setores regulados, não basta que uma plataforma seja funcional.
Ela precisa ser controlável, auditável, segregável, resiliente e compatível com exigências de compliance.
A proteção de dados críticos, a rastreabilidade de acessos, a criptografia, o gerenciamento de identidades, a segregação de funções e a capacidade de recuperação são partes integrantes desse contexto.
A IBM posiciona o IBM Z com foco em segurança avançada, incluindo casos de uso como detecção de fraudes em tempo real no setor financeiro.
Também destaca recursos de resiliência cibernética, como o IBM Z Cyber Vault, voltado à proteção de dados críticos e recuperação após ataques, incluindo ameaças como ransomware.
Esse ponto é cada vez mais importante. A discussão contemporânea sobre resiliência não se limita à disponibilidade tradicional. Não basta manter o sistema no ar.
É necessário preservar integridade, detectar manipulação indevida de dados, recuperar ambientes comprometidos, resistir a ataques cibernéticos e demonstrar conformidade regulatória.
Nesse sentido, o Mainframe tem uma vantagem cultural. Ele nasceu em ambientes nos quais controle, segregação, auditoria e operação disciplinada eram mandatórios.
Enquanto muitas plataformas modernas estão reforçando agora práticas de governança que cresceram em importância com regulação, risco cibernético e soberania de dados, o Mainframe já traz essa mentalidade em seu desenho operacional.
Isso não significa que o Mainframe seja automaticamente seguro. Nenhuma plataforma é.
Configurações inadequadas, acessos excessivos, falhas de governança, ausência de atualização, dependência de conhecimento antigo e integrações mal desenhadas podem criar riscos relevantes. Mas significa que a plataforma oferece fundamentos robustos para ambientes que exigem controle rigoroso.
Ao longo do tempo, a nomenclatura e as gerações da plataforma evoluíram. System/360, System/370, ESA, S/390, zSeries, System z e IBM Z representam uma trajetória de continuidade e renovação.
Cada geração incorporou avanços de processamento, memória, I/O, virtualização, segurança, criptografia, disponibilidade e integração.
A letra z passou a ser associada à ideia de zero downtime, reforçando a proposta de alta disponibilidade.
Embora nenhuma tecnologia deva ser tratada como infalível, essa ambição comunica bem o posicionamento da plataforma: suportar operações que não podem parar.
A modernização do IBM Z também acompanhou mudanças no tipo de workload. Além das cargas tradicionais em COBOL, CICS, IMS e DB2, a plataforma passou a dialogar com Java, Linux, containers, APIs, DevOps, observabilidade, automação, criptografia avançada e AI.
O objetivo deixou de ser apenas manter sistemas antigos e passou a incluir a modernização contínua de aplicações críticas.
Essa evolução é relevante porque desmonta uma visão simplista do Mainframe como tecnologia congelada. O que se mantém é a continuidade arquitetural.
O que muda são as formas de integração, os recursos de hardware, os modelos operacionais e as possibilidades de desenvolvimento.
A fase mais recente dessa trajetória é a aproximação entre Mainframe e Artificial Intelligence. Essa aproximação não deve ser vista apenas como marketing tecnológico.
Há uma lógica prática por trás dela. Muitos dos dados mais críticos das organizações continuam nos sistemas centrais.
Em bancos, seguradoras, governos e grandes empresas, transações de alto valor, registros oficiais, históricos de clientes, saldos, limites, contratos e eventos operacionais continuam fortemente conectados ao Mainframe.
A aplicação de AI próxima desses dados pode reduzir movimentos desnecessários, diminuir latência, preservar segurança e permitir decisões em tempo real.
A IBM afirma que AI on IBM Z permite aplicar machine learning diretamente aos dados transacionais, evitando movimentação de dados e habilitando insights em tempo real.
Esse posicionamento é particularmente relevante para casos como detecção de fraude, análise de risco, classificação de transações, monitoramento de comportamento, prevenção de anomalias, automação operacional e assistência ao desenvolvimento.
Em ambientes financeiros, por exemplo, a capacidade de avaliar uma transação no momento em que ela ocorre pode ser muito mais valiosa do que analisá-la posteriormente em uma plataforma analítica separada.
O IBM z17, anunciado em 2025, reforça essa direção. A IBM o descreveu como um Mainframe totalmente projetado para a era da AI, com disponibilidade geral prevista para 18 de junho de 2025 e com o IBM Spyre Accelerator esperado a partir do quarto trimestre de 2025.
A página do produto destaca aceleração de AI, uso de modelos múltiplos, insights em tempo real, segurança aprimorada, produtividade e resiliência.
A questão aqui não é imaginar que todo processamento de AI será feito no Mainframe. Isso não faria sentido.
Modelos massivos, treinamento em larga escala, experimentação científica e workloads intensivos de GPU continuarão sendo executados em ambientes especializados.
O ponto é outro: certas inferências, decisões e automações podem fazer sentido perto dos dados transacionais e dos sistemas de registro. Nessa fronteira, o Mainframe pode ter um papel importante.
Ao se observar a história completa, parece claro que o principal ativo do Mainframe não é apenas performance. Também não é apenas compatibilidade. O principal ativo é confiança operacional.
Confiança, nesse contexto, significa que a plataforma foi testada durante décadas em ambientes de altíssima criticidade.
Significa que processos de negócio inteiros foram construídos ao seu redor. Significa que equipes operacionais desenvolveram práticas, controles e rotinas altamente especializadas.
Significa que reguladores, auditores e executivos aprenderam a confiar na estabilidade desses sistemas.
Essa confiança tem valor econômico.
Uma plataforma que processa transações críticas com previsibilidade reduz riscos.
Uma plataforma que mantém disponibilidade elevada protege receita.
Uma plataforma que preserva integridade de dados evita perdas financeiras, impactos reputacionais e sanções regulatórias.
Uma plataforma que permite rastreabilidade facilita auditorias.
Uma plataforma que já contém décadas de regras de negócio reduz incerteza funcional.
O problema é que confiança operacional nem sempre aparece bem em apresentações comparativas de custo.
Ela não é facilmente capturada em um gráfico de preço por core, preço por gigabyte ou preço por instância. Mas aparece rapidamente quando há uma falha grave, uma migração mal-sucedida, uma indisponibilidade sistêmica ou uma inconsistência de dados.
É por isso que o Mainframe continua presente nos setores em que o erro custa caro.
Apesar de sua força técnica, a plataforma enfrenta um desafio real: pessoas. Muitos profissionais experientes de Mainframe estão se aposentando ou se aproximando dessa fase.
Ao mesmo tempo, novas gerações de desenvolvedores tendem a se formar em linguagens, ferramentas e ambientes mais associados à web, cloud, mobile, dados e AI.
Esse desalinhamento cria riscos. A escassez de profissionais pode aumentar custos, dificultar manutenção, reduzir velocidade de evolução e concentrar conhecimento em poucos especialistas.
Esse talvez seja um dos maiores riscos estratégicos para empresas dependentes de Mainframe.
A resposta não deve ser apenas contratar mais especialistas, até porque o mercado pode não oferecer volume suficiente.
Deve ser construída uma estratégia de gestão de conhecimento, renovação de talentos, documentação assistida por ferramentas, automação de testes, modernização de ambientes de desenvolvimento, integração com práticas DevOps e uso de AI para apoiar compreensão de código legado.
Ferramentas modernas podem ajudar novos profissionais a interagir com sistemas antigos de forma mais produtiva.
Ambientes de desenvolvimento integrados, pipelines automatizados, análise estática de código, geração de documentação, testes automatizados e assistentes baseados em AI podem reduzir a barreira de entrada.
O futuro do Mainframe, portanto, dependerá menos da capacidade de preservar a cultura antiga e mais da capacidade de traduzi-la para uma nova geração de engenharia.
Um dos maiores equívocos no debate sobre Mainframe é tratar modernização como sinônimo de migração.
Em muitas organizações, essa associação criou programas caros, longos e arriscados, movidos mais por pressão tecnológica do que por uma análise clara de valor.
Modernizar pode significar muitas coisas. Pode significar melhorar a experiência do desenvolvedor. Pode significar criar APIs para funcionalidades centrais. Pode significar automatizar testes. Pode significar reduzir dependências batch. Pode significar separar dados analíticos de dados transacionais. Pode significar reescrever módulos específicos. Pode significar mover partes menos críticas para cloud. Pode significar melhorar observabilidade. Pode significar otimizar consumo de capacidade. Pode significar revisar contratos. Pode significar atualizar práticas de segurança. Pode significar documentar regras de negócio.
A migração é apenas uma das alternativas. Em alguns casos, ela será correta. Em outros, será perigosa. Em muitos, será economicamente questionável. A decisão deve ser baseada em critérios arquiteturais e de negócio, não em preferência ideológica por uma plataforma.
Uma abordagem madura deveria classificar o portfólio Mainframe em grupos. Sistemas com alta criticidade e alto acoplamento talvez devam ser modernizados no lugar.
Componentes com baixa criticidade e alto custo talvez devam ser migrados. Regras de negócio reutilizáveis talvez devam ser expostas por APIs. Dados necessários para analytics talvez devam ser replicados de forma governada.
Processos batch talvez devam ser redesenhados. Interfaces antigas talvez devam ser substituídas. O core transacional talvez deva permanecer.
Essa visão evita tanto o conservadorismo excessivo quanto a modernização imprudente.
O destino mais provável para o Mainframe não é o desaparecimento imediato, mas a integração cada vez mais sofisticada em arquiteturas híbridas.
As empresas continuarão usando cloud para inovação, elasticidade, analytics, AI, colaboração, SaaS e canais digitais. Também continuarão usando sistemas centrais para registros críticos, processamento transacional e operações reguladas.
A arquitetura vencedora será aquela capaz de orquestrar esse conjunto com clareza. Isso exige governança de APIs, gestão de dados, observabilidade ponta a ponta, segurança integrada, identidade federada, automação, controle de custos, resiliência e arquitetura empresarial.
Nesse cenário, o Mainframe deve deixar de ser tratado como um bloco isolado dentro do data center.
Ele deve ser tratado como um asset tecnológico estratégico, com funções claras dentro do operating model de tecnologia. Essa mudança de postura é importante.
Quando uma plataforma é tratada apenas como legado, tende a ser negligenciada. Quando é tratada como asset crítico, tende a ser governada, modernizada e otimizada.
O desafio das organizações não é amar ou odiar o Mainframe. O desafio é saber o que fazer com ele.
A história do Mainframe oferece algumas lições importantes para qualquer executivo de tecnologia.
A primeira lição é que longevidade não significa obsolescência. Algumas tecnologias permanecem porque foram bem desenhadas, porque resolvem problemas fundamentais e porque continuam evoluindo. O tempo, por si só, não torna uma plataforma irrelevante.
A segunda lição é que compatibilidade tem valor. Em um mercado frequentemente obcecado por rupturas, é fácil esquecer que empresas precisam preservar investimentos, reduzir riscos e garantir continuidade. A inovação precisa conviver com a responsabilidade operacional.
A terceira lição é que arquitetura importa. O Mainframe não sobreviveu apenas por força comercial. Ele sobreviveu porque sua arquitetura foi adequada a certos problemas críticos. Escalabilidade, segurança, disponibilidade, isolamento e integridade são características difíceis de improvisar depois.
A quarta lição é que custo precisa ser analisado em múltiplas dimensões. O mais barato em infraestrutura pode não ser o mais barato em risco. O mais barato em licenciamento pode não ser o mais barato em reengenharia. O mais barato no curto prazo pode não ser o mais econômico no ciclo completo.
A quinta lição é que modernização inteligente é seletiva. Nem tudo precisa ser reescrito. Nem tudo deve ser preservado. Nem tudo deve ir para cloud. Nem tudo deve ficar no Mainframe. A boa arquitetura é aquela que posiciona cada capability tecnológica no lugar mais adequado.
Quando se olha para a trajetória completa, impressiona perceber que o Mainframe atravessou praticamente todas as eras da computação empresarial.
Ele nasceu na era da computação centralizada. Adaptou-se à era transacional. Sobreviveu à ascensão dos minicomputadores. Resistiu ao computador pessoal. Conviviu com cliente-servidor. Integrado à web, sustentou internet banking, reservas, pagamentos e grandes sistemas governamentais. Abriu-se ao Linux. Conectou-se por APIs. Passou a fazer parte da arquitetura híbrida. Agora, busca se posicionar também na era da AI.
Poucas plataformas podem reivindicar uma história semelhante. A maioria das tecnologias corporativas tem ciclos muito mais curtos. Linguagens, frameworks, bancos de dados, servidores de aplicação, appliances, ferramentas de integração e modelos arquiteturais surgem, crescem, amadurecem e declinam em poucas décadas, às vezes em poucos anos.
O Mainframe, por sua vez, continua sendo parte da espinha dorsal de muitas organizações críticas.
Essa permanência não deve ser romantizada. A plataforma tem desafios reais. Custo, talentos, complexidade, dependência de fornecedores, percepção de legado, dificuldade de mudança e integração com modelos modernos são temas legítimos. Porém, também não deve ser subestimada. Sua capacidade de reinvenção é rara.
É interessante voltar à provocação inicial: o que teria acontecido se os custos do Mainframe fossem mais baixos?
Provavelmente, a pressão por substituição teria sido menor. Muitos debates arquiteturais teriam sido conduzidos de forma menos emocional e mais técnica.
O Mainframe talvez tivesse sido mais amplamente adotado para workloads que exigem alta densidade, resiliência e segurança.
Algumas empresas talvez tivessem evitado arquiteturas distribuídas excessivamente complexas, criadas para escapar de custos centrais, mas que depois geraram novos custos de integração, observabilidade, segurança e operação.
Por outro lado, custos mais baixos também poderiam ter reduzido a pressão por inovação externa. Parte da evolução tecnológica ocorreu justamente porque empresas buscaram alternativas mais flexíveis e acessíveis.
A concorrência de plataformas abertas, cloud e arquiteturas distribuídas forçou o Mainframe a se modernizar. Nesse sentido, a pressão competitiva foi saudável.
Talvez a conclusão mais equilibrada seja reconhecer que o Mainframe foi, ao mesmo tempo, vítima e beneficiário de sua própria proposta de valor.
Seu custo elevado limitou sua expansão e alimentou projetos de substituição. Mas sua robustez, confiabilidade e capacidade transacional sustentaram sua permanência. A plataforma não venceu por ser barata. Venceu, nos contextos em que continuou relevante, por ser difícil de substituir.
O futuro do Mainframe não deve ser lido como uma repetição simples do passado. A plataforma continuará relevante, mas seu papel será mais seletivo.
A tendência não parece ser um retorno ao mundo totalmente centralizado. Tampouco parece realista imaginar uma eliminação rápida dos Mainframes em grandes organizações reguladas.
O mais provável é uma convivência. Mainframes continuarão sustentando sistemas críticos, especialmente em setores que dependem de processamento transacional massivo, segurança, integridade e resiliência.
Ao mesmo tempo, esses ambientes serão cada vez mais integrados a cloud, plataformas digitais, AI, analytics e automação.
A modernização será menos sobre trocar uma plataforma por outra e mais sobre reduzir acoplamentos, aumentar interoperabilidade, melhorar governança de dados, acelerar desenvolvimento, renovar talentos e aplicar AI de forma pragmática sobre sistemas e dados críticos.
O Mainframe do futuro talvez seja menos visível para o usuário final, mas continuará essencial em determinadas cadeias de valor. Ele será uma plataforma de bastidor, mas um bastidor crítico. Uma infraestrutura de confiança. Um motor transacional. Um repositório de conhecimento histórico. Um componente da arquitetura híbrida empresarial.
A palavra legado costuma carregar uma conotação negativa em tecnologia. Muitas vezes, legado é usado como sinônimo de antigo, rígido, caro e problemático.
Mas legado também pode significar algo que foi herdado porque teve valor. Algo que permanece porque sustentou a organização. Algo que precisa ser cuidado, modernizado e governado, não simplesmente descartado.
O Mainframe é talvez um dos melhores exemplos dessa ambiguidade. Ele é legado no sentido histórico. Mas não é apenas legado no sentido depreciativo. É uma plataforma viva, que continua sendo atualizada, reposicionada e integrada a novas ondas tecnológicas.
Sua história mostra que a tecnologia corporativa não evolui apenas por substituição. Muitas vezes, ela evolui por camadas. O novo não elimina imediatamente o antigo.
O digital não apaga o transacional. A cloud não elimina automaticamente o data center. AI não substitui a necessidade de dados confiáveis. A modernização não elimina a importância da continuidade.
Ao final, talvez o Mainframe continue existindo porque as empresas continuam precisando daquilo que ele sempre prometeu entregar: confiança em escala.
E, em um mundo cada vez mais digital, volátil, regulado, integrado e exposto a riscos cibernéticos, confiança em escala continua sendo uma das capacidades tecnológicas mais valiosas que uma organização pode possuir.
Refletir sobre minha jornada desde os primórdios da minha carreira em tecnologia, onde comecei programando em plataformas Mainframe, até o presente, é uma experiência que evoca tanto nostalgia quanto admiração pelo avanço da tecnologia.
Durante essas décadas, sempre ouvi rumores sobre o suposto ocaso do Mainframe.
No entanto, a resiliência dessa tecnologia tem sido notável, desafiando repetidamente as previsões de sua obsolescência.
Iniciei minha carreira de maneira despretensiosa, aprendendo Cobol, CICS, JCL e DB2 em um curso de dois meses financiado por uma bolsa de estudos.
Naquela época, muitos colegas questionavam a lógica de investir tempo em uma tecnologia considerada por muitos como ultrapassada.
Olhando para trás, após mais de vinte anos, sou profundamente grato pelas oportunidades que essa escolha inicial me proporcionou.
Essa trajetória não apenas moldou minha carreira profissional, mas também enriqueceu minha vida com experiências inestimáveis.
A plataforma Mainframe, embora não seja a primeira opção para projetos novos — especialmente com o crescimento exponencial da computação em nuvem —, continua desempenhando um papel crucial em diversos setores.
Sua capacidade de processar grandes volumes de dados e sua confiabilidade em operações críticas ainda são comparativamente superiores em muitos aspectos.
O caso da Allianz, onde a migração do Mainframe para Linux foi meticulosamente planejada e executada, ilustra que a transição de tecnologias legadas é possível, mas não sem desafios significativos.
A migração requer um planejamento extensivo, colaboração entre múltiplas equipes e uma gestão eficaz das mudanças.
Neste contexto, a participação e o comprometimento de todos na organização são indispensáveis, tanto no nível técnico quanto no gerencial.
É fundamental reconhecer que, apesar dos benefícios financeiros e operacionais a longo prazo que tais migrações prometem, elas não são simples nem desprovidas de riscos.
As empresas devem realizar uma avaliação meticulosa, considerando não apenas o impacto tecnológico, mas também o alinhamento estratégico com os objetivos de negócio.
O retorno sobre o investimento em tais projetos, como destacado no exemplo da Allianz, geralmente é percebido ao longo de vários anos.
Adicionalmente, a evolução contínua do Mainframe, que agora inclui capacidades modernas como integração com a inteligência artificial e a computação em nuvem, sinaliza que essa tecnologia ainda pode se adaptar e permanecer relevante em um mercado em constante transformação.
Enquanto observamos o desenvolvimento da competição entre plataformas tradicionais e soluções em nuvem, a decisão de migrar ou manter operações em Mainframes deve ser baseada em uma análise cuidadosa das necessidades específicas e capacidades organizacionais.
Finalmente, como líder e profissional de TI que acompanhou e liderou transformações significativas, afirmo que a adaptação e inovação são fundamentais para a sobrevivência e o sucesso em um ambiente empresarial que evolui rapidamente.
Neste processo, preservar o conhecimento e integrar novas tecnologias de forma estratégica são essenciais para garantir a competitividade e a eficácia operacional no futuro.
O conteúdo apresentado neste website, incluindo o framework, é protegido por direitos autorais e é de propriedade exclusiva do CIO Codex. Isso inclui, mas não se limita a, textos, gráficos, marcas, logotipos, imagens, vídeos e demais materiais disponíveis no site. Qualquer reprodução, distribuição, ou utilização não autorizada desse conteúdo é estritamente proibida e sujeita às penalidades previstas na legislação aplicável

Uma introdução clara ao CIO Codex Framework, com os pilares essenciais para transformar TI em valor. Ideal para ter a visão geral do framework.

Mais de 20 anos de prática em TI concentrados em um livro que mostra, na prática, como estruturar e evoluir áreas de tecnologia a partir do CIO Codex.

Tenha acesso ao framework detalhado, conteúdos premium, análises, mapas, atualizações constantes e uma comunidade dedicada à evolução da TI.
Uma introdução clara ao CIO Codex Framework, com os pilares essenciais para transformar TI em valor. Ideal para ter a visão geral do framework.
Mais de 20 anos de prática em TI concentrados em um livro que mostra, na prática, como estruturar e evoluir áreas de tecnologia a partir do CIO Codex.
Tenha acesso ao framework detalhado, conteúdos premium, análises, mapas, atualizações constantes e uma comunidade dedicada à evolução da TI.